強化学習(reinforcement Learning)は、試行錯誤を通じて価値を最大化する行動を学習する方法の一つである。強化学習は学習方法の概念の一つであるので、強化学習を行うには、個々問題に応じて、行動を行う主体(エージェント)、エージェントを取り巻く環境、エージェント取り得る行動の種類、そして環境からのフィードバック(価値・報酬)といったものを設定していく必要がある。例えば、自動運転を考えたとき、エージェントを車、環境を実世界の道路空間、行動をハンドル・アクセル・ブレーキ、報酬をスタート地点から事故を起こす地点までの距離として問題設定することができる。
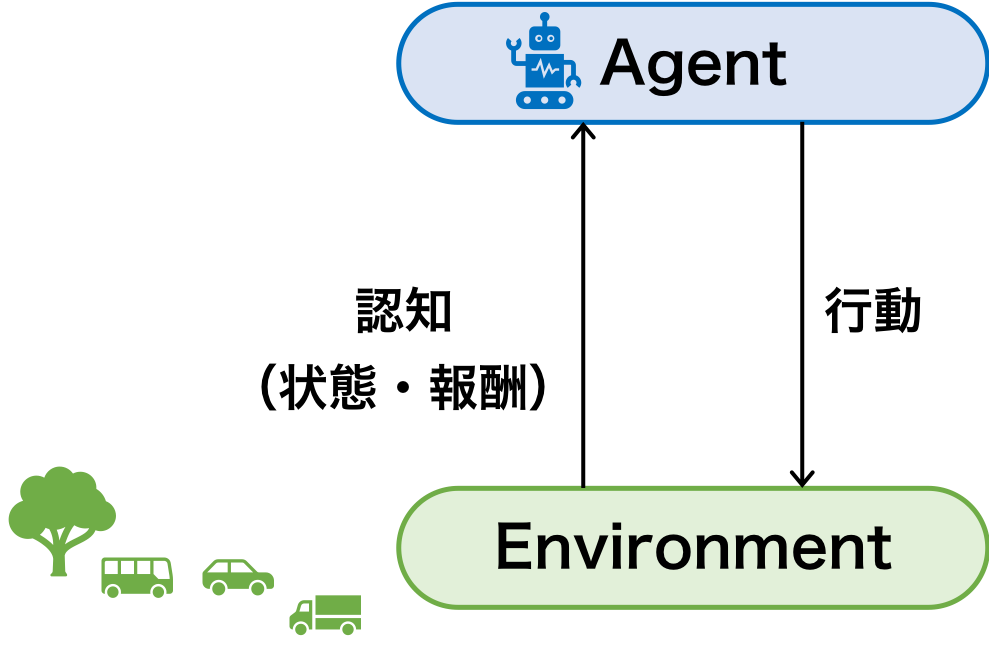
強化学習の学習は、エージェントと環境のやりとりを通じて行う。エージェントは、車のほかにロボットであったりする。また、環境は、実世界の空間だけでなく、コンピュータ上で作り出されたシミュレーション空間であってもよい。学習の流れとしては、エージェントが、センサーなどを通して、光や音声など環境の状態を認知し、それに基づいて行動する。そして、エージェントの行動が、環境の状態を変化させる。そのため、エージェントが次の行動を行うために、再び環境の状態を認知する必要がある。このように、エージェントは、環境の認知と環境への行動を繰り返すこによって、一連の行動を行なっていく。そして、こうした一連の行動が終了したときに、そのれまでの行動に応じた報酬が与えられる。例えば、車の自動運転では、事故を起こすまでを一連の行動として捉えたとき、強化学習を用いると、報酬(事故を起こすまでの距離)を最大化する行動を選択できるようになる。
強化学習の学習アルゴリズムは複数存在する。環境に対する事前知識量と意思決定を行うための情報量によって、効率的な学習アルゴリズムが異なってくる。例えば、コイン投げの問題を考えてみる。コイン A とコイン B を投げた後に、エージェントにコイン A またはコイン B を選択させる。そして、選択されたコインがオモテならば 1 ポイントを与える。このとき、もしエージェントが「コイン A とコイン B にバイアスが存在する」と「コイン A とコイン B がオモテになる確率」がすでに知っている場合は、エージェントはすべての組み合わせを一通り実行して、最適な行動を学習する。これは、ダイナミックプログラミングとよばれるアルゴリズムで実現できる。これに対して、エージェントが「コイン A とコイン B にバイアスが存在する」を知っているが、「コイン A とコイン B がオモテになる確率」を知らない場合は、エージェントはベイズ推定等を介して、最適な行動を学習する。
