データ収集からモデルが実用化されるまでを一つのワークフローとして考えたとき、このワークフローをデータ収集、データ前処理、モデル構築および実用化の 4 段階にわけることができる。このワークフローの中で、データ収集が最も時間がかかる段階である。データ収集は、ワークフローの中で 8 割前後の時間を占める場合もある。

データの前処理
測定などにより収集されたデータ(特徴量)には、異常値や欠損値が含まれる場合がある。こうした異常値や欠損値は、機械学習時に、悪影響を及ぼす。そのため、学習を始める前に、異常値や欠損値に対して、除去したり、あるいは線形補間したりする。線形補間を行う場合に、トレーニングデータの線形補間を行うときに、テストデータの情報を使用しないように注意する必要がある。
異常値や欠損値を対処した後に、必要に応じて、各特徴量に対して正規化(標準化)を行う。正規化は、学習時に、各特徴量を平等に扱うための前処理にあたる。例えば、気温と降水量という 2 つ特徴量が存在したとき、気温は 0-35 °C 前後のスケールで、降水量は 0-800mm 前後のスケールとなる。このとき、両者をそのまま学習に使ったとき、降水量のスケールが大きいので、降水量の変化が、気温の変化に比べて、学習の結果に強く影響を与えてしまう。このように、単位の異なる特徴量をそのままで学習に使用したとき、特徴量同士の扱いは平等でなくなる。
正規化には、データの取りうる範囲を 0 以上かつ 1 以下に変換したり、データ全体が平均 0 分散 1 となるように変換したりする方法などがある。特徴量の分布が一様分布ならば、0 以上 1 以下の値に変換したり、特徴量の分布が正規分布ならば、平均 0 分散 1 の正規分布に変換する。
正規化を施した後に、必要に応じて特徴選択・次元削減を行う。特徴量が高次元の場合に、相関の高い特徴量が複数含まれたりする。相関の高い特徴量が複数存在すると、過学習などを起こしてしまう可能性がある。そのため、このような高次元な特徴量を含むデータに対して、特徴選択・次元削減を行い、相関の高い特徴量を減らす作業が一般的に行われている。
モデル構築
前処理が施されたデータに対して、学習と評価を繰り返すことで、最適な予測モデルを求める。機械学習を使用して予測モデルを構築するとき、まずデータをトレーニングデータ(training set)とテストデータ(test set)に分ける必要がある。そして、トレーニングデータを使って予測モデルを構築(予測モデルのパラメーターを計算)し、テストデータで予測モデルの性能を評価する。
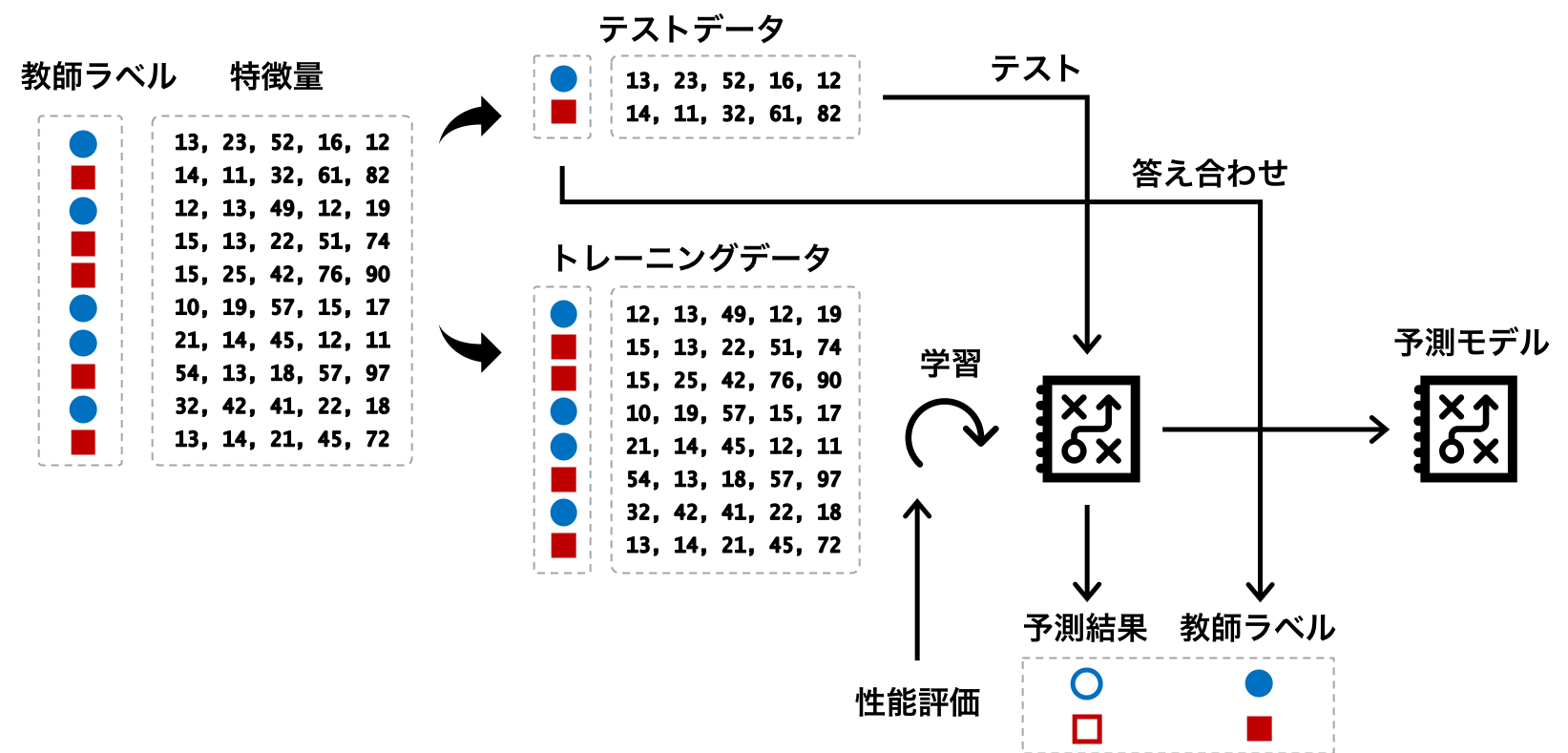
機械学習の学習アルゴリズムには、ロジスティック回帰、決定木やサポートベクターマシンなど、多様に存在する。これらのアルゴリズムは、それぞれの得意とする部分がある。データの特徴(サンプル数、特徴量など)、データに含まれるノイズの大きさなどによって、得意とするアルゴリズムが異なってくる。そのため、予測モデルを作る上で、トレーニングデータを使って複数のアルゴリズムで予測モデルを作成し、続けてテストデータを使って各予測モデルの性能を評価する。そして、最高性能を出した学習アルゴリズムで作成された予測モデルを採択して実用化する。
学習アルゴリズムにハイパーパラメーターが存在する場合、最適なハイパーパラメーターの値を決めるために、トレーニグデータ(training set)をさらにトレーニングデータ(training set)とテストデータ(検証データ)に分ける必要がある。この場合のテストデータは、モデルを評価するためのテストデータ(test set)と区別するために、検証データ(validation set)と呼ぶ場合が多い。
実用化
学習と評価の繰り返しにより、最適な予測モデルが構築されると、その予測モデルに新しいデータを代入して、予測させることができる。新しいデータを代入するとき、新しいデータに対しても正規化など前処理を施す必要がある。新しいデータに対して前処理するときに、学習時に用いた前処理用のパラメーターと同一のものを使う必要がある。そのため、前処理の段階で使ったパラメーター情報などは保存しておく必要がある。
References
- Python Machine Learning, Second Edition, Chapter 1. Packt Publishing. 2017.