カテゴリ変数は、通常文字列として表される場合が多い。このなかで、服のサイズを表す S、M、L や被害程度を表す strong、medium、weak のように大小関係を持つカテゴリ変数がある。このような変数を順序特徴量という。これに対して、気象を表す sunny、cloudy、rainy、snowy などのように大小関係のない特徴もあり、これを名義特徴量という。

これらの特徴量は通常文字列として記録されるが、そのままでは機械学習の入力データとして使用できない。機械学習で使えるような形にするには、解析者自身がこれらの文字列を数値に置き換える必要がある。順序特徴量の場合は、大小関係を考慮してカテゴリ変数を数値に変更すればよい。名義特徴量の場合は、カテゴリ間に大小関係が生じないように one-hot encoding などの方法で数値化を行う。
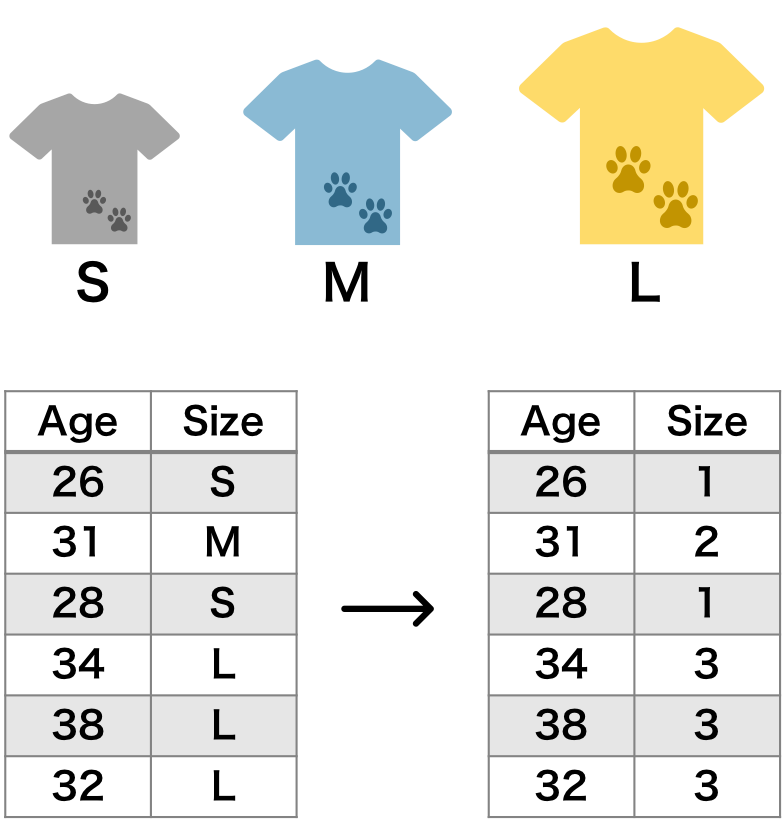
順序特徴量
順序特徴量の場合、その大小関係を保持させて整数値に変換することで対応できる。例えば、S = 1、M = 2、L = 3 のように変換することができる。
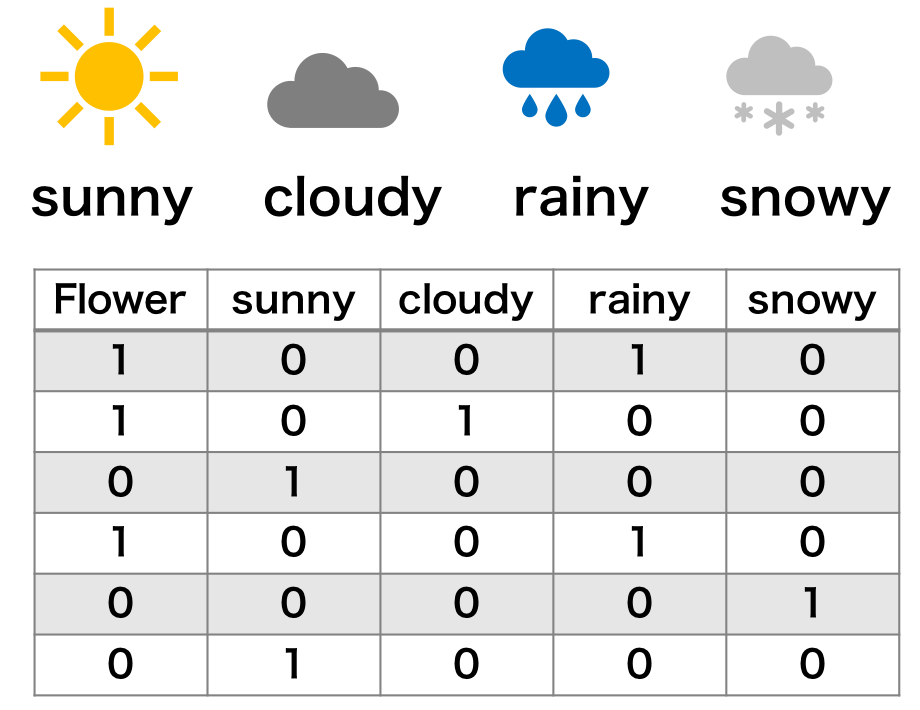
名義特徴量
one-hot encoding
名義特徴量の場合は、ダミー変数を制定して、各文字ラベルをダミー変数に置き換えることができる。例えば、下の表のように sunny、cloudy、rainy、snowy の 4 つのカテゴリに対応するためのダミー変数を 4 つ用意して、sunny であれば sunny 特徴量に 1 を、他の 3 特徴量に 0 として表すことができる。このような置換手法を one-hot encoding という。
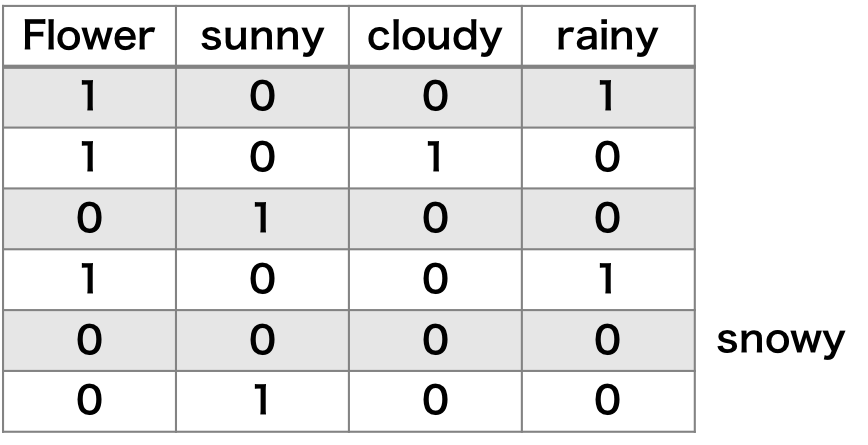
dummy encoding
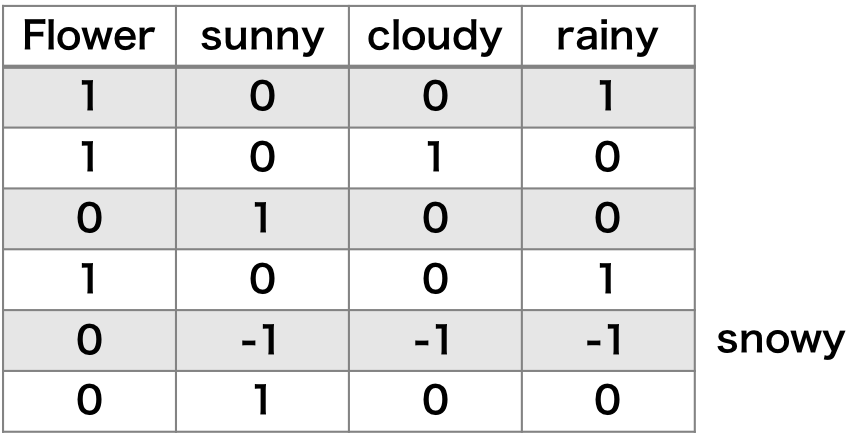
また、カテゴリが 4 つあるとき、4 つのダミー変数を用意する必要はない。例えば、sunny、cloudy および rainy に対応するダミー変数を用意して、この 3 つのダミー変数がすべて 0 のときは自動的に snowy を意味するようになる。このような置換手法を dummy encoding という。one-hot encoding に比べ、この dummy encoding の方が多重共線性を回避することができる。
effecct encoding
one-hot encoding の多重共線性を回避するもう一つの方法として、effect encoding がある。effect encoding では、dummy encoding のとき、すべての要素が 0 のベクトルを -1 に置き換えたものに等しい。