検証曲線は、ハイパーパラメーターの値と予測性能の関係を示した折れ線グラフである。検証曲線の横軸は、ハイパーパラメーターの値であり、縦軸は評価指標である。評価指標は、訓練データを使った時の評価指標と検証データを使った時の評価指標の両方をプロットする。両者の指標で描かれた曲線の離れ具合で、最適なハイパーパラメーターの取りうる値を大まかに把握することができる。
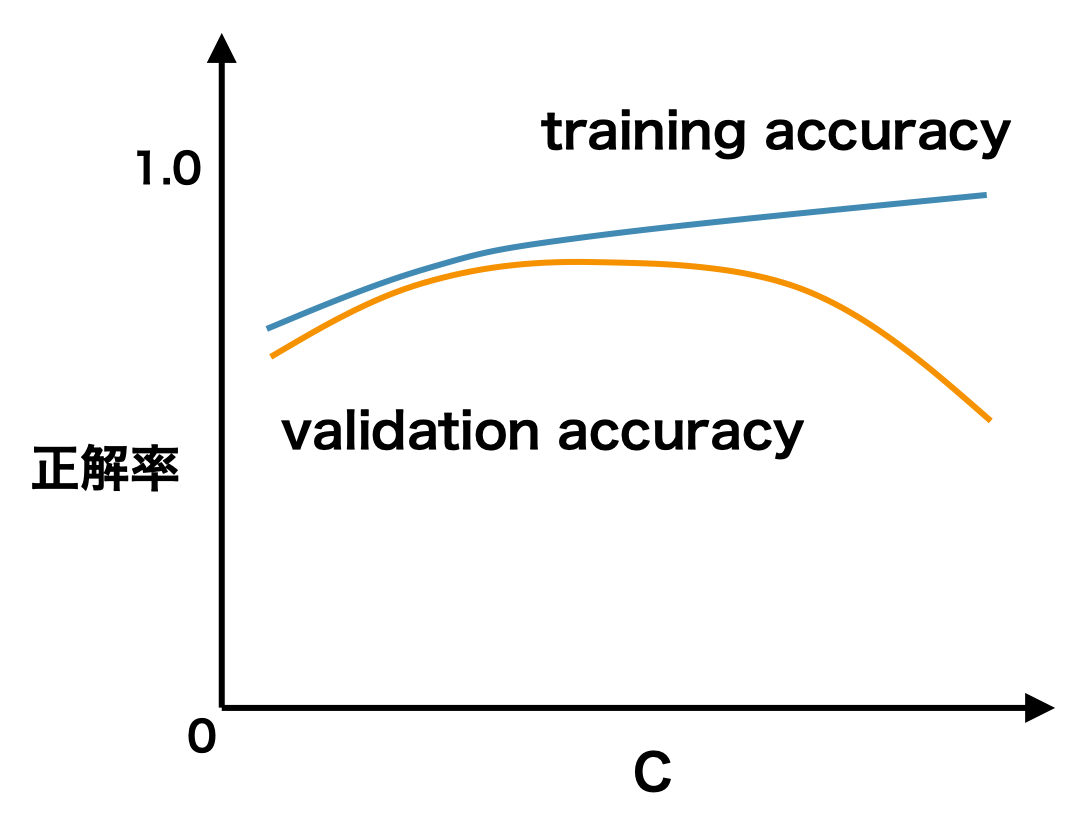
例えば、下図のような検証曲線の場合、あるハイパーパラメーターの値が小さいとき、訓練データと評価データに対するモデルの予測精度は、両方とも低いままである。これは学習データが少なくて、学習不足を起こしていると考えられる。
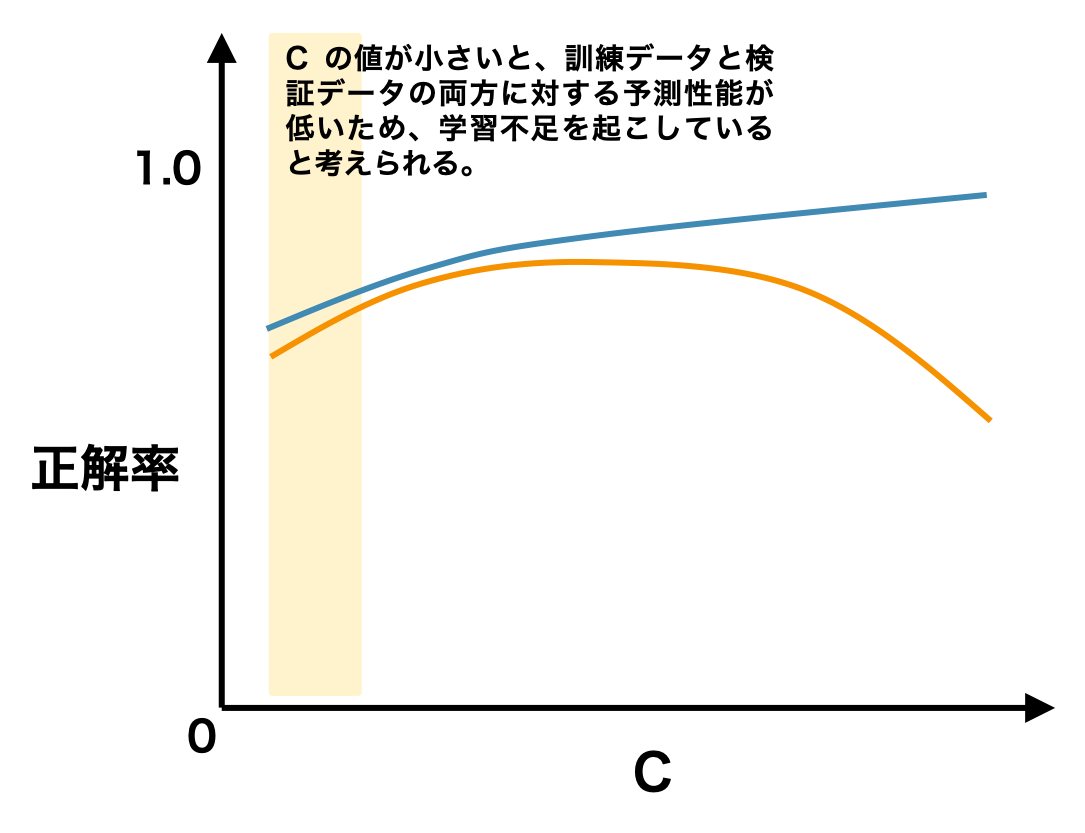
一方で、ハイパーパラメーターの値が大きくなると、訓練データと評価データに対するモデルの予測精度が乖離し始める。つまり、モデルは学習データに対してうまく対応できるが、未知のデータにうまく対応できなくなる過学習の状態になる。
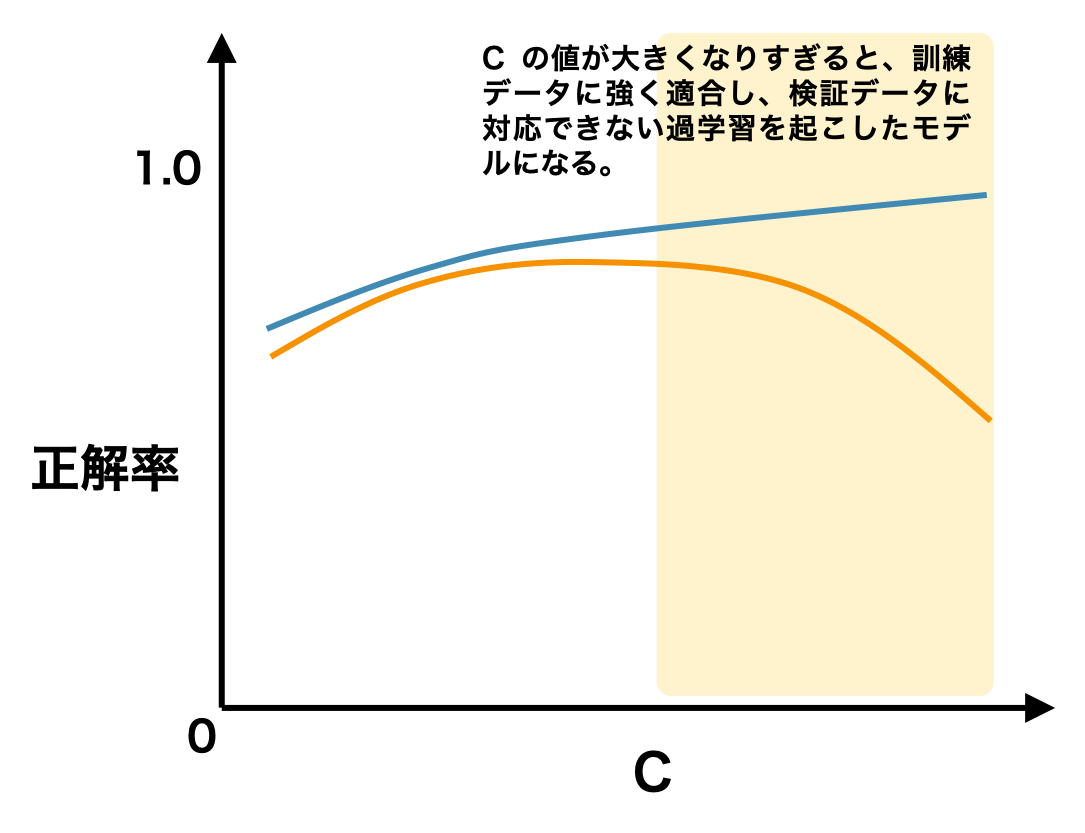
検証曲線を描くことで、最適なハイパーパラメーターの取りうる値を大まかに把握することができる。
sklearn を利用して検証曲線を描く方法
乳がんのデータセットに対して、SVM でモデルを作成するとき、その validation curve は次のように描かれる。オレンジ色の線は training data に対するモデルの予測精度で、青色の線は validation data に対するモデルの予測精度である。薄く塗りつぶされた範囲は、クロスバリデーションにより求められた精度の最大値と最小値の範囲を表している。次の図から、このデータセットに関して、SVM のハイパーパラメーター C の最適解は、100 近くにあると考えられる。
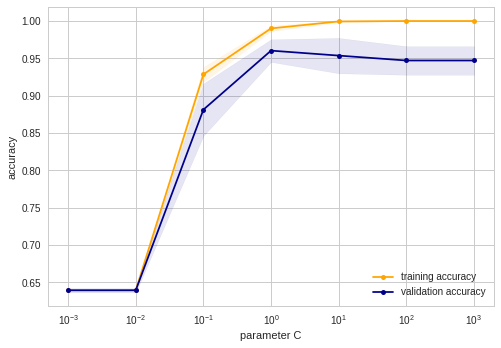
Python モジュールの scikit-learn では validation_curve メソッドを使用することで、validation curve の座標を計算できる。ランダムシードを設定していないので、実行するたびに、異なる validation curve が描かれる。
References
- Python Machine Learning, Second Edition, Chapter 1. Packt Publishing. 2017.