複数のアルゴリズムを比較して、最適なアルゴリズムを決定したいときは、入れ子構造の交差検証(nested k-fold cross validation)を使用する。一般的な交差検証は、一つのアルゴリズムの中で、最適なハイパーパラメータを決めるものであった。例えば、SVM を使って予測器を作るならば、交差検証により最適なカーネル関数およびカーネル関数に必要なハイパーパラメータ gamma や C などを決定し、最後に、最適なハイパーパラメータを持つ SVM(gamma, C) に、これまでに使っていなかったテストデータを与えて、汎化性能を評価する。これに対して、入れ子構造の交差検証は、複数のアルゴリズムを比較して、その中から最適なアルゴリズムを決定する際に利用する。例えば、SVM とランダムフォレストを比較して、この中から予測精度が最も高いアルゴリズムを決定し、その汎化性能を評価するための交差検証の方法である。
アルゴリズム間の比較において、入れ子構造の交差検証を必要とされるのは、比較を 2 回行う必要があるからである。1 回目の比較は、各アルゴリズムのハイパーパラメータを決める際に必要である。SVM とランダムフォレストを比較して最適なアルゴリズムを決める際に、まず最適な SVM と最適なランダムフォレストを決める必要がある。最適な SVM を決めるためには、SVM のハイパーパラメータ gamma や C を交差検証により決める必要がある。この 1 回目の交差検証で決定された最適な SVM(gamma, C) を決める。また、同様な交差検証データセットを使用して、ランダムフォレストの最適なハイパーパラメータ n_estimators や max_depth を決めることができる。これにより最適なランダムフォレスト RF(n_estimators, max_depth) が決定される。
2 回目の比較は、1 回目の比較で得られた最適な SVM および最適なランダムフォレストの比較である。すなわち、SVM(gamma, C) と RF(n_estimator, max_depth) の比較である。この比較は、ホールドアウト法で比較できると考えがちであるが、データセットの分け方によってアルゴリズム間の比較が不公平にならないように、交差検証を行う必要がある。これが 2 回目の交差検証である。
ここまでの比較において、最適なアルゴリズムが決定される。例えば、SVM(gamma, C) が RF(n_estimator, max_depth) よりも予測性能が高かったとする。しかし、これまでの評価において得られた SVM(gamma, C) の予測性能は、交差検証用のデータを使って評価したものである。つまり、学習データと検証データの組み合わせを何回か行って、そこから評価したものである。このように評価した性能は、未知のデータに対する汎化性能ではない。そこで、最後の最後に取っておいたテストデータを SVM(gamma, C) に入力して、この SVM の未知のデータに対する汎化性能を評価する。
以上のことを踏まえると、まずデータセットの全体からテストデータを確保する。続けて、残ったデータセットを 5-fold 交差検証できるように 5 つのサブユニットに分ける。ここで分けた 5-fold 交差検証用のデータセットは最適な SVM と最適なランダムフォレストを比較する際に利用する。この比較を行うために、まず最適な SVM と最適なランダムフォレストを決める必要がある。そこで、この時点で訓練データセットとして使える 4 サブセットをさらに 2 分割して、2-fold 交差検証用のデータセットにわける。こうすれば、2-fold 交差検証により最適な SVM あるいは最適なランダムフォレストを決めることができるようになる。データの分け方を図示すると次のようになる。
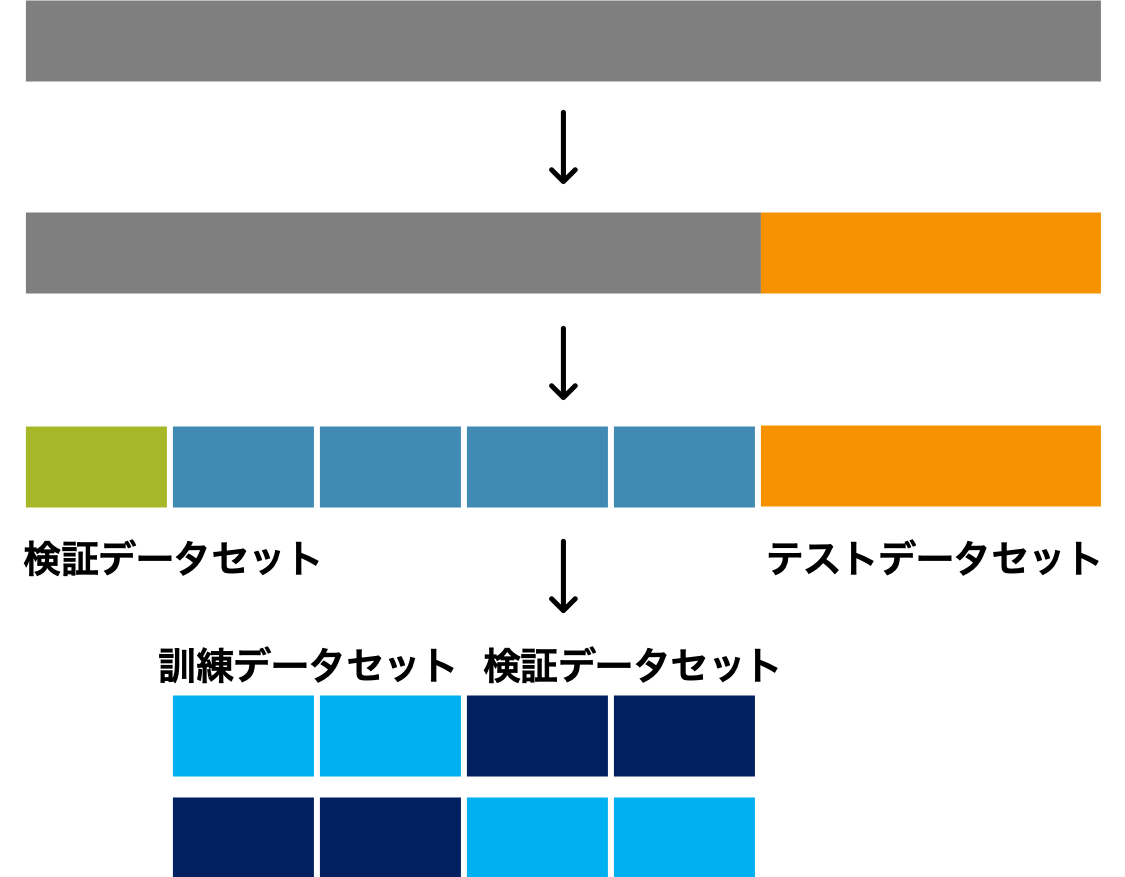
入れ子構造をした交差検証は、複数のアルゴリズム間の比較を行って、その中から最適なアルゴリズム(モデル)を決めて、その汎化性能を評価する目的で使われる。これに対して、(複数のアルゴリズム間の中から最適なモデルを決めるのではなく、)複数アルゴリズムそれぞれの最適なモデルを決める目的であれば、入れ子構造の交差検証にする必要はない。つまり、最適な SVM モデルと最適なランダムフォレストモデルの両方を作って、両者の優劣を評価したり考察したりしなければ、上述の 2 回目の比較を行う必要はない。この場合は普通の交差検証を行えばよい。
検証は、なんらかの目的が設定され、その目的に達しているかどうかを評価するための作業である。目的が異なれば検証方法も異なる。必ずしも研究に 2 種類以上のアルゴリズムを使っているから入れ子構造の交差検証しなければならない、というこはない。検証を行うにあたって、データの構造やアルゴリズムにとらわれすぎず、目的にあった検証方法を考えて使うべきである。
scikit-learn を利用した入れ子構造の交差検証
次の例は、乳がんのデータセットを使って、SVM と random forest の 2 種類のアルゴリズムを使って作成した予測機の予測精度を比べる例である。モデルの評価結果から、random forest よりも SVM の方が予測精度が高いことがわかる。