機械学習の目標は未知の予測することであるから、その未知データに対する予測性能を正しく評価する必要がある。そのために、現在持っている全データセットを訓練データや検証データ(見かけ上の未知のデータ)に分けて、学習と評価を正しく行なっていかなければならない。
モデルが一つしか存在しないとき、現在持っているデータを訓練データと評価データに分けて、訓練データでモデルの構築し、評価データでモデルの評価を行えばよい。しかし、多くの場合、機械学習においては、複数のモデルを作成して、それらのモデルの性能を比較してもっとも性能の高いモデルを選ぶという手順がある。例えば、気温、降水量、日射量を使って小麦の終了を予測するモデルを考えるとき、気温だけを使って収量を予測するモデル 1、気温と降水量を使って収量を予測するモデル 2、気温・降水量・日射量をすべて使って収量を予測するモデル 3 などのように、複数の変数(ハイパーパラメーター)の組みあわせでモデルを構築することができる。このとき、訓練データでモデル 1 の学習を行い、評価データでモデル 1 の評価を行う、続いてモデル 2 やモデル 3 などにおいても同様な訓練データと評価データを使って、学習と評価を繰り返すことになる。このようにして、学習と評価を繰り返して得られる高性能なモデルは、現在の評価データに対して最適な性能を示すモデルになってしまう。これを違った角度から見れば、評価データも(ハイパーパラメーター選択のための)学習に使っているということになる(Sebastian et al, 2017)。そして、こうして得られた高性能なモデルは、評価データに対して適合してあるため、将来に取られる未知のデータに対しても有効であるという保証がなくなる。
そこで、少ないデータセットを有効活用して、モデルの汎化性能を正しく評価できるようなデータセット分割方法が考えられている。代表的なものがホールドアウト法や k-fold 交差検証法がある。このページではホールドアウト法について述べている。
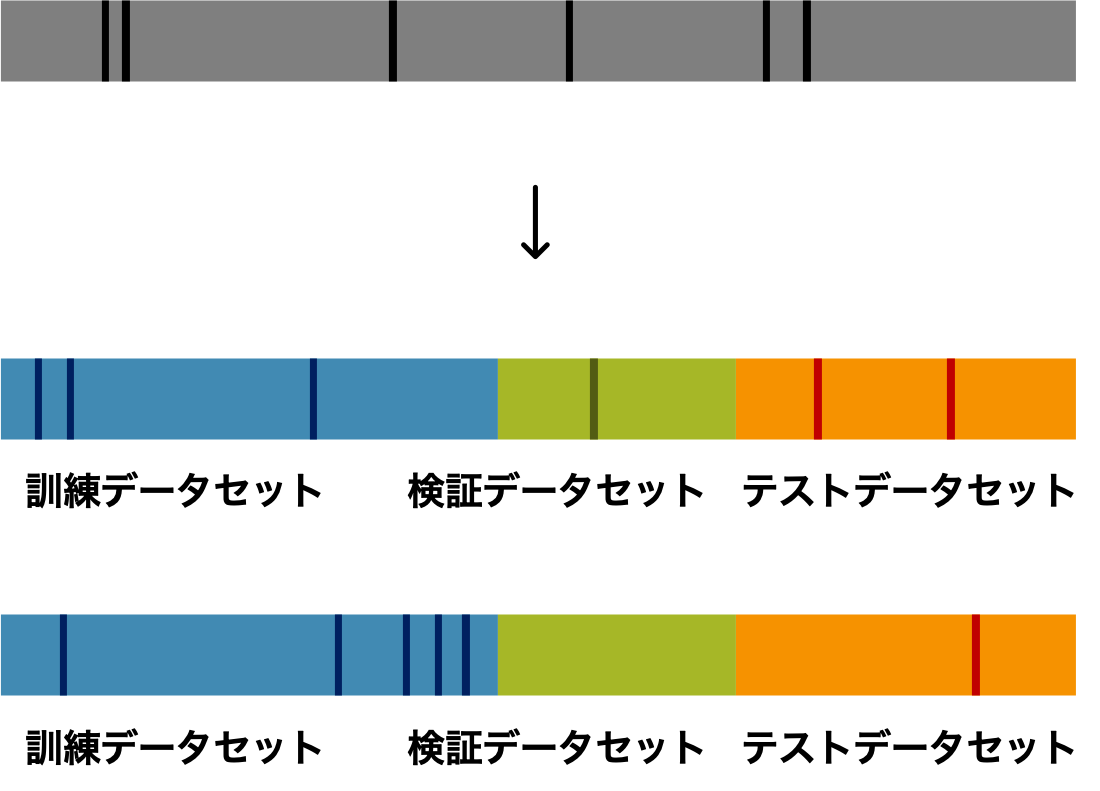
ホールドアウト法は、全訓練データを 3 つのサブセットに分ける方法である。すなわち、あらかじめ、全訓練データを、モデルを学習用、ハイパーパラメーターの組み合わせ評価用、そして最終的な汎化性能評価用の 3 つのサブセットに分けてから、最適なモデルを構築していくことになる。これらのサブセットを訓練データ(trainig data)、評価データ(validation data)、そしてテストデータ(test data)と呼ぶ。
全データを 3 つのデータセットに分けたのちに、モデル 1 を訓練データで学習し、検証データで検証する。そして、モデル 2 やモデル 3 などに対しても、同様な訓練データで学習し、検証データで検証する。そして、検証結果を比べて、これらのモデルの中から最適なモデルを選ぶ。こうして選ばれたモデルに、訓練データと検証データを合わせて訓練データとして代入し学習を行い、最後にテストデータで最終評価を行う。

しかし、ホールドアウト法でモデルの汎化性能を評価できない場合が考えられる。とりわけ、元々のデータ量が少ないとき、それらを訓練データ、評価データ、そしてテストデータに分けるとき、その分け方がモデルの最終評価に大きく影響する。例えば、観測ノイズを多く含むデータのほとんどが偶然に訓練データあるいはテストデータに振り分けられたりする場合が考えられる。このようなケースを回避するために、k-fold 交差検証法 などを一般的に使われる。
References
- Python Machine Learning, Second Edition, Chapter 1. Packt Publishing. 2017.