k 近傍法 (k-nearest neighbor classifier; k-NN) は、教師あり学習の 1 つであり、主に分類問題を解くのに利用される。k 近傍法は、他の機械学習アルゴリズムとは異なり、教師データからモデルのパラメーターを推測するというステップが存在しない。k 近傍法の学習というのは、入力された教師データをそのまま記憶するだけである。そのため、k 近傍法は怠惰学習アルゴリズムの 1 つでもある。
k 近傍法による分類は、分類対象のサンプルと教師データに含まれているサンプルの距離に基づいて行われる。教師データを丸暗記したモデルに対して、未知のサンプルを入力すると、このモデルは、未知のサンプルと丸暗記した教師データ中の全サンプルとの距離を計算する。次に、教師データの中から、未知のサンプルに最も近い k 個のサンプルを選ぶ。選んだ k 個の教師データのサンプルが属しているクラスタを調べ、最も多く見られるクラスタを未知のデータのクラスタとする。
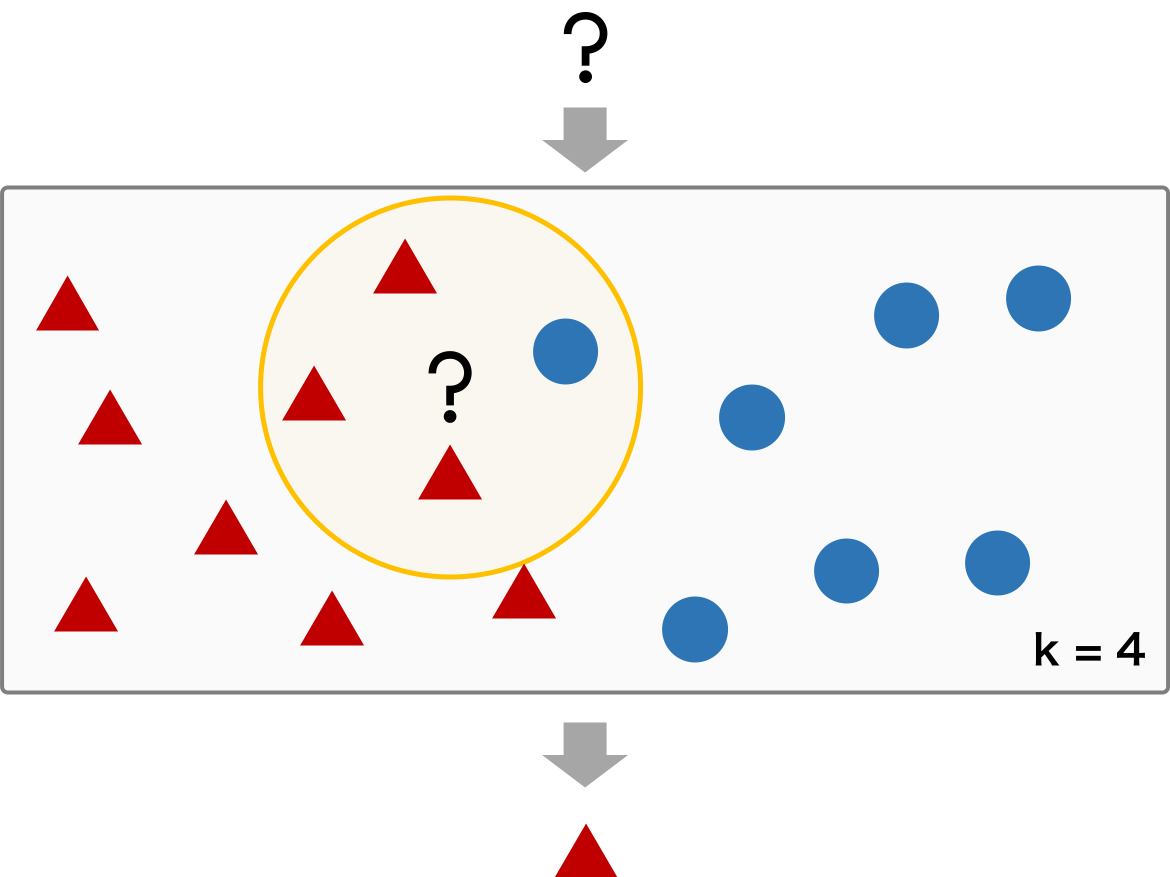
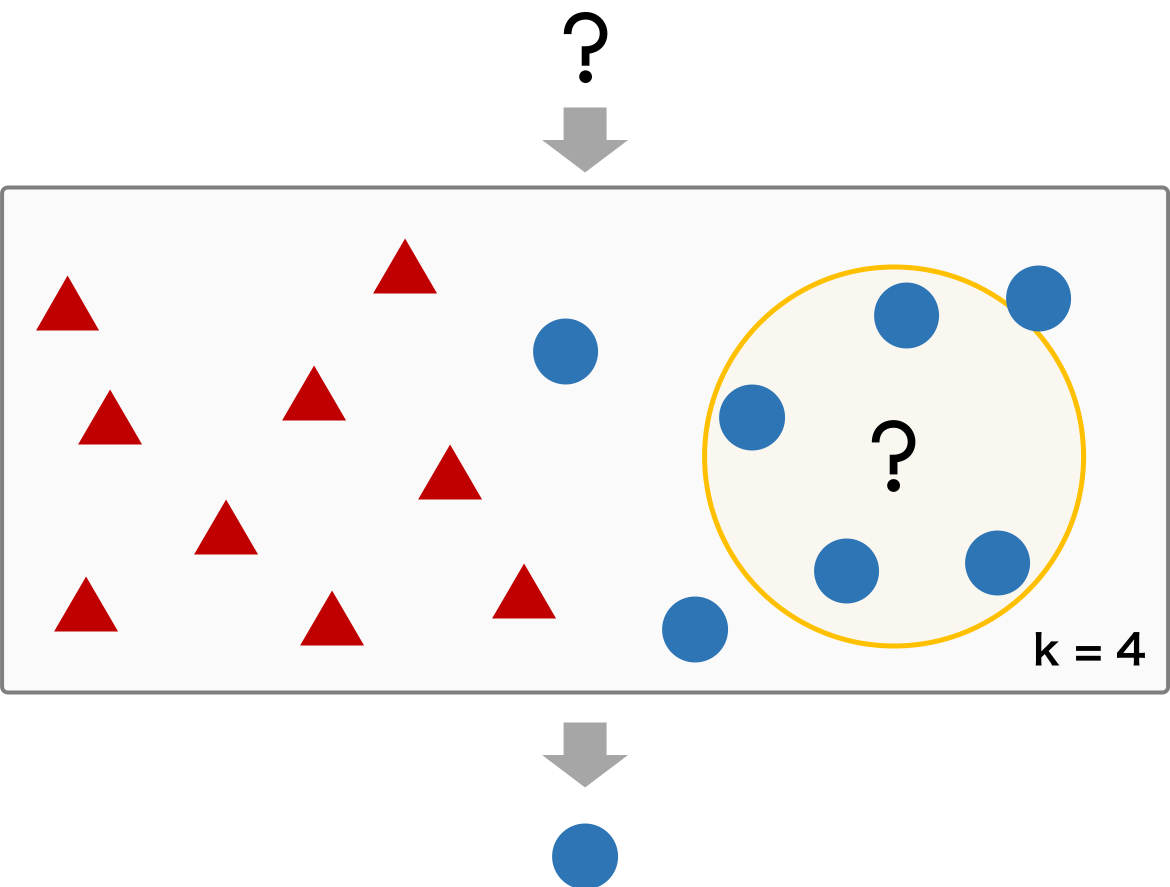
k 近傍法で作られたモデルは、距離に基づいてデータを分類しているため、適切な距離を選ぶことが非常に重要となってくる。距離は特徴量に応じて決められ、ユーグリッド距離やマンハッタン距離などがある。また、k についても、データセットの特徴にあった数値を選ぶ必要がある。
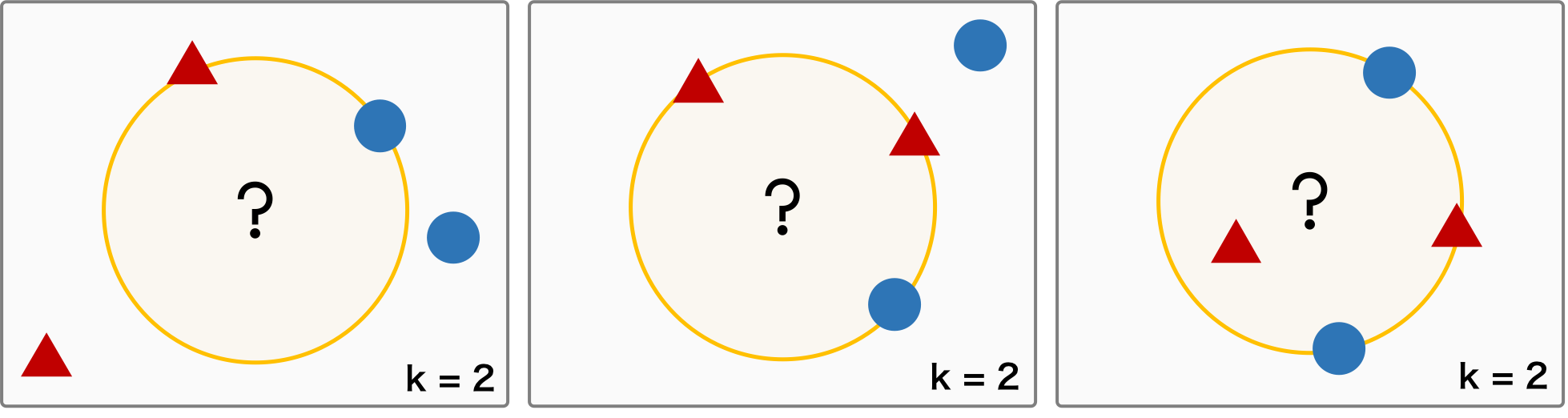
k の選び方とデータセットの特徴によって、以下のように、答えが一意的に決まらない場合が考えられる。例えば、k = 2 を考えたとき、距離のもっとも近い 2 要素を確認したら別々のクラスだったり、あるいは、同じ距離の要素が 3 つ以上存在したりする場合が考えられる。このような状況では、k の値かを大きくしたり、あるいは奇数にしたりすることで回避できる。また、距離に対して重みを考えて、距離が近いほど重みを大きくすることでも、このような状況を回避することできる。