アンサンブル法は、いくつかの予測モデル(C1, C2, C3, ...)を組み合わせて物事を予測し、それらのモデルの予測結果に対して、多数決の原理に基づいて最終的な予測結果を出す方法である。分類問題における多クラス分類においては、相対多数決(最頻値)により決める。また、モデルの出力が確率などの数値である場合は、それらの数値の平均をとるといった方法も使われている。
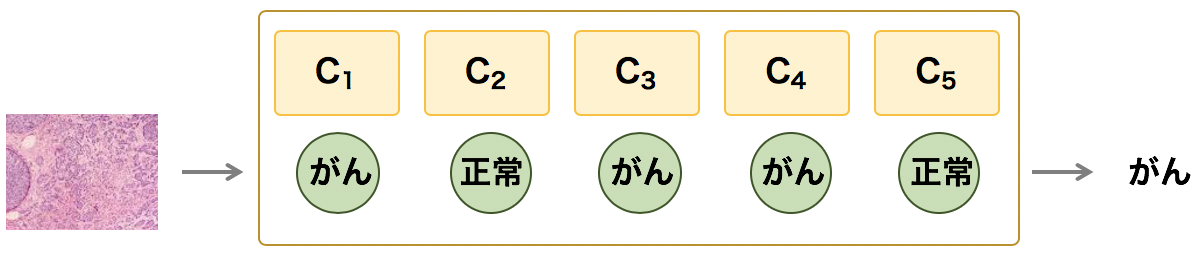
アンサンブル法のアプローチで作成されたモデルの性能が最も高くなるのは、アンサンブルを構成している予測モデルが互いに独立である必要がある。このような(アンサンブルを構成する)予測モデルを作成するには、同じ教師データに対して、ロジスティック回帰、サポートベクトルマシンや決定木などのアルゴリズムを使用して予測モデル C1, C2, C3, ... を作成し、これらのモデルをまとめてアンサンブルを構築する。
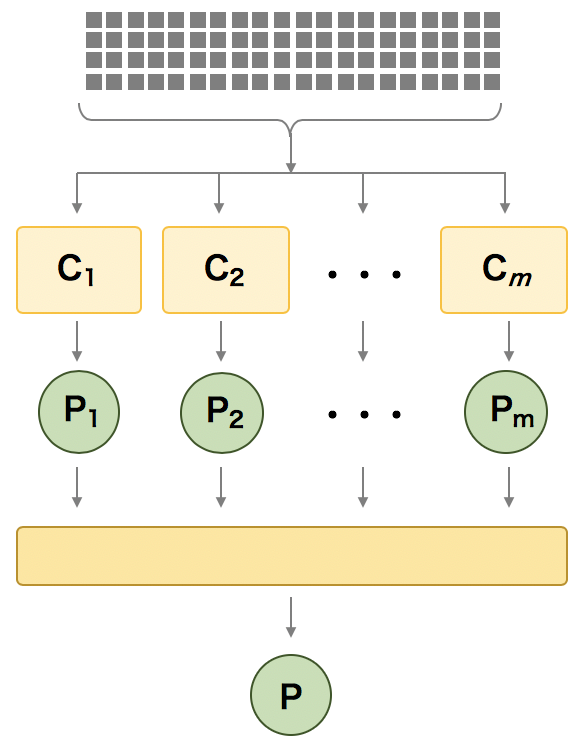
しかし、この方法だと、同じ教師データを使ってモデルを作成しているため、バリアンスが高くなりがちである。これに対して、バリアンスを低く抑えたり、バイアスとバリアンスのトレードオフをうまく調整することができる、バギングやスタッキングなどのアルゴリズムが使われている。
アンサンブル法は、複数の予測モデルの予測結果をまとめて予測結果を出力するので、個々の単独な予測モデルよりも一般的に性能が高い。しかし、アンサンブルの性能は、単独の予測モデルの性能に比べて著しく高いというわけではない*。その反面、アンサンブルは複数の予測モデルで構成されているため、モデル作成のための計算コストが非常に大きい。
バギング
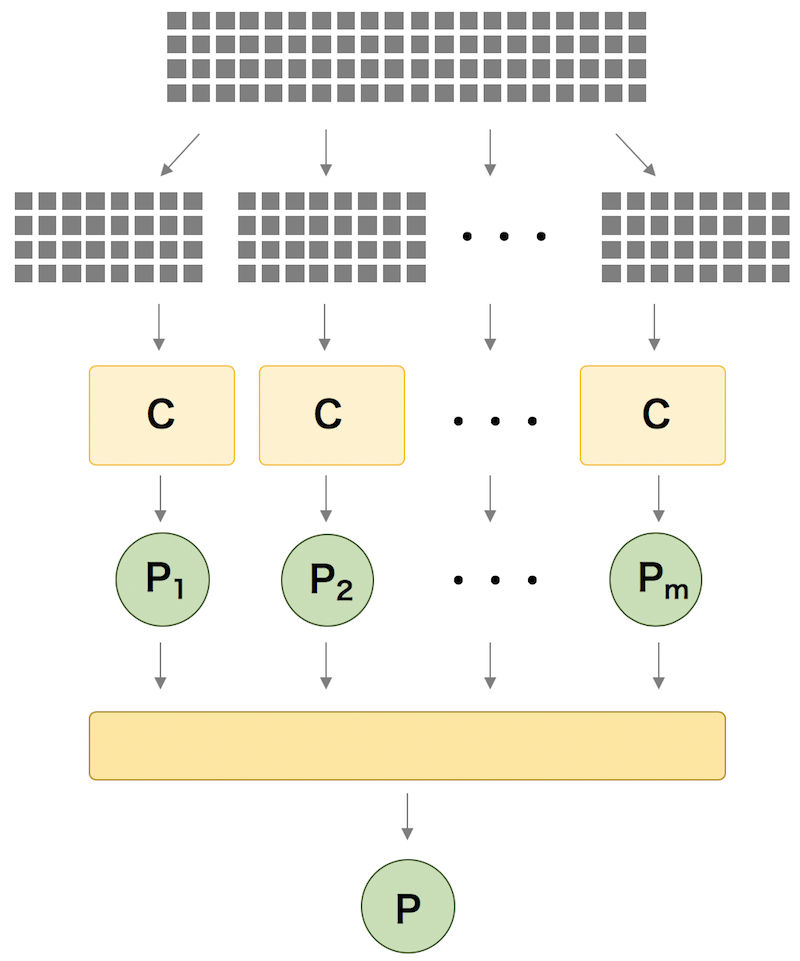
バギングは、アンサンブル法の 1 つであり、上述したシンプルなアンサンブル法に比べて、教師データの与え方が異なっている。シンプルなアンサンブル法では、アンサンブルを構成する個々の予測モデルを作成する際に同じ教師データを用いていた。これに対して、バギングでは、教師データから復元抽出により抽出した標本(ブートストラップ標本)を使用して個々の予測モデルを作成している。ランダムフォレストが、バギングを使った決定木としてみなすことができる。
ブースティング
ブースティングもアンサンブル学習法の 1 つである。ブースティングでは、まず教師データから非復元抽出により抽出した標本で 1 つ目の予測モデルを作成する。続いて、1 つ目のモデルで正しく予測できなかった教師データを使って 2 つ目の予測モデルを作成する。このように、1 つ前のモデルで間違えたデータを次のモデルの学習時に含めて、モデルを次々と強化していく。ブースティングには様々なバリエーションがあるが、初めて提唱されたブースティングのアルゴリズムは次のようになっている。
- 教師データから非復元抽出により教師データのサブセット D1 を作成する。D1 を使って予測モデル C1 を作成する。
- 教師データから非復元抽出により教師データのサブセット D2 を作成する。D1 のうち C1 が間違って予測したデータのうち 50% を D2 に加えて、これらのデータセットを使って予測モデル C2 を作成する。
- C1 と C2 の予測結果が異なっているデータを抽出して D3 とする。D3 を使って予測モデル C3 を作成する。
- C1, C2, C3 の 3 つの予測モデルでアンサンブルを構成する。
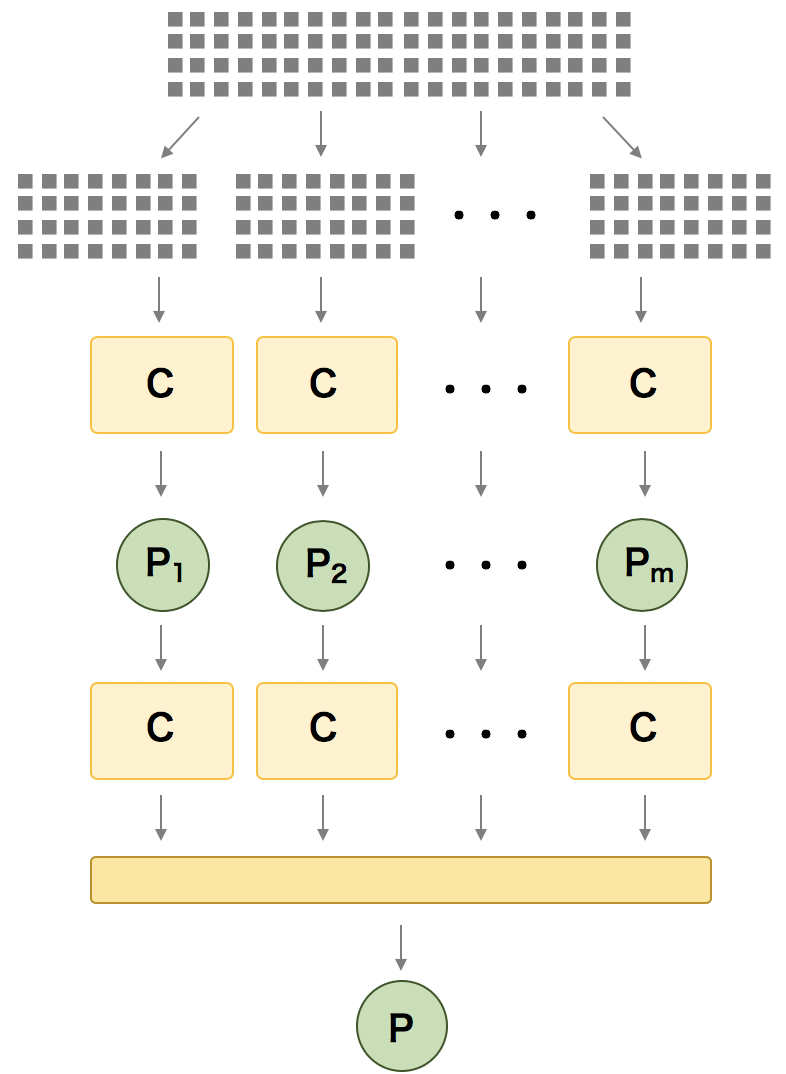
スタッキング
スタッキングもアンサンブル法の 1 つである。アンサンブルを複数レイヤーに重ねたような構造をしている。例えば、第 1 層目には、複数の予測モデルからなるアンサンブルを構築する。2 層目には、1 層目から出力された値を入力とするアンサンブルを構築する。
References
- Python 機械学習プログラミング 達人データサイエンティストによる理論と実践 インプレス. 2016, 7:213-245.