決定木(decision tree)は、データを複数のクラスに分類する教師あり学習のアルゴリズムの一つである。学習結果が木構造で出力されるため、非常に解釈しやすい。Python の scikit-learn ライブラリー中の tree.DecisionTreeClassifier クラスを利用することで、決定木モデルの作成と予測を行うことができる。
scikit-learn による決定的の作成
次のサンプルコードは、scikit-learn に保存されている iris のデータセットを使って、決定木を作る例である。このデータセットに、アヤメの種類とガクの長さと幅および花弁の長さと幅がセットとなって保存されている。次のコードでは、具体的に、ガクの長さと幅および花弁の長さと幅がセットでアヤメの種類を予測する決定木を作成する例である。学習を行うときに、決定木の層の数を指定する必要があり、ここでは最大で 3 層(max_depth = 3)とした。
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
if __name__ == '__main__':
iris = datasets.load_iris()
print(iris.data)
## [[ 5.1 3.5 1.4 0.2]
## [ 4.9 3. 1.4 0.2]
## [ 4.7 3.2 1.3 0.2]
## [ 4.6 3.1 1.5 0.2]
## ..
## [ 6.2 3.4 5.4 2.3]
## [ 5.9 3. 5.1 1.8]]
print(iris.target)
## [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
## 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
## 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
## 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
## 2 2]
## split data into training data (80%) and test data (20%).
train_x, test_x, train_y, test_y = train_test_split(iris.data, iris.target, test_size = 0.2)
clf = DecisionTreeClassifier(max_depth = 3)
clf = clf.fit(train_x, train_y)
predicted_y = clf.predict(test_x)
score = accuracy_score(test_y, predicted_y)
print(score)交差検証
決定木を作成するとき、層の数を指定する必要がある。層数は交差検証(クロスバリデーション)により最適な値にする。次の例は、scikit-learn の cross_val_score メソッドを使用して、層数を 2〜9 まで試して、性能評価をしている。層数が 4 以上のとき、性能がほとんど上がっていないことを確認できる。
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
if __name__ == '__main__':
iris = datasets.load_iris()
max_depth_list = [2, 3, 4, 5, 6, 7, 8, 9]
for max_depth in max_depth_list:
clf = DecisionTreeClassifier(max_depth = max_depth)
score = cross_val_score(estimator = clf, X = iris.data, y = iris.target, cv = 10)
print([max_depth, score.mean()])
## [2, 0.94666666666666666]
## [3, 0.95999999999999996]
## [4, 0.95333333333333337]
## [5, 0.95333333333333337]
## [6, 0.95333333333333337]
## [7, 0.95333333333333337]
## [8, 0.95333333333333337]
## [9, 0.95999999999999996]決定木を作成する上で、層の数の他に、不純度の指標(エントロピー、ジニ係数、分類誤差など)もあらかじめ与える必要がある。ハイパーパラメーター が複数あるとき、scikit-learn の GridSearchCV メソッドを使うと便利。
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
if __name__ == '__main__':
iris = datasets.load_iris()
params = {'max_depth': [2, 3, 4, 5, 6, 7, 8, 9],
'criterion': ['gini', 'entropy']}
clf = GridSearchCV(DecisionTreeClassifier(), params, cv = 10)
clf.fit(X = iris.data, y = iris.target)
print(clf.best_estimator_)
## DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=3,
## max_features=None, max_leaf_nodes=None,
## min_impurity_decrease=0.0, min_impurity_split=None,
## min_samples_leaf=1, min_samples_split=2,
## min_weight_fraction_leaf=0.0, presort=False, random_state=None,
## splitter='best')
print(clf.best_score_)
##0.96
print(clf.best_params_)
## {'criterion': 'gini', 'max_depth': 3}可視化
決定木モデルの可視化は、Python の pydotplus ライブラリーを利用する。その際、決定木の構造は PDF として出力される。
import pydotplus
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
if __name__ == '__main__':
iris = datasets.load_iris()
clf = DecisionTreeClassifier(max_depth = 3)
clf = clf.fit(iris.data, iris.target)
dot = StringIO()
export_graphviz(clf, out_file = dot)
graph = pydotplus.graph_from_dot_data(dot.getvalue())
graph.write_pdf("graph.pdf")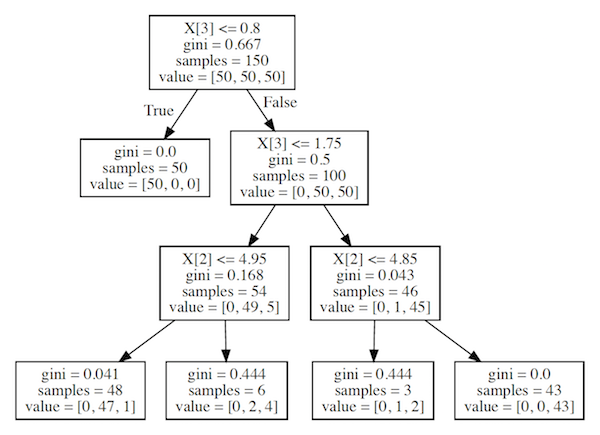
References
- . Python による機械学習入門. Ohmsha 2016.
- scikit-learn で決定木分析 (CART 法). Python でデータサイエンス
- cross validation + decision trees in sklearn. Stackoverflow