torchvision パッケージには VGG、ResNet などの有名な物体分類用のアーキテクチャが実装されている。有名なアーキテクチャを利用して物体分類モデルを作成する場合は、ゼロからアーキテクチャを構築するよりも、torchvision に実装されているアーキテクチャを呼び出して使うと便利である。このページでは、torchvision から VGG16 とよばれるアーキテクチャを呼び出して、物体分類モデルを作る方法を示す。
まず、必要なパッケージ群を読み込む。matplotlib は学習精度をグラフとして可視化する時に利用する。torch および torchvision は物体分類用のモデルを作成する際に利用する。
import matplotlib.pyplot as plt
import torch
import torchvision次に学習用画像および検証用画像を、PyTorch の ImageFolder 関数で読み込めるようなフォルダ構造になるように整理する。ここでは PlantVillage 画像データの一部(ダウンロード)を使う。
data_transforms = {
'train': torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(224),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'valid': torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
train_data_dir = 'drive/My Drive/datasets/plantvillage/train'
valid_data_dir = 'drive/My Drive/datasets/plantvillage/valid'
image_datasets = {
'train': torchvision.datasets.ImageFolder(train_data_dir, transform=data_transforms['train']),
'valid': torchvision.datasets.ImageFolder(valid_data_dir, transform=data_transforms['valid'])
}
dataloaders = {
'train': torch.utils.data.DataLoader(image_datasets['train'], batch_size=16, shuffle=True),
'valid': torch.utils.data.DataLoader(image_datasets['valid'], batch_size=16)
}
dataset_sizes = {
'train': len(image_datasets['train']),
'valid': len(image_datasets['valid'])
}
class_names = image_datasets['train'].classes
print(class_names)
## c_0 c_1 c_2 c_3 c_4続けて、torchvision に実装されている VGG16 のアーキテクチャを呼び出して、その出力層を 5 (len(class_names))カテゴリとなるように変更する。その後、そのモデルを GPU 上に送る。なお、次のコードの最初の行で、 pretrained=True とすると、ImageNet で訓練済みの VGG16 を利用して途中から学習を進めることができる(転移学習)。
net = torchvision.models.vgg16(pretrained=False)
num_ftrs = net.classifier[6].in_features
net.classifier[6] = torch.nn.Linear(num_ftrs, len(class_names))
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
net = net.to(device)損失関数および学習アルゴリズムなどを定義する。このページで使っているサンプルデータは難しいデータなので、学習率とスケジューラの調整が非常に難しい。数時間調整した結果、結局次のようなパラメーターである程度うまくいくことがわかった。
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.00005)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.1)上で定義したデータおよびアルゴリズムなどを使用して、学習と検証を繰り返す。また、各エポックにおいて学習精度と検証精度を記録しておく。
num_epochs = 40
acc_history = {'train': [], 'valid': []}
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch + 1, num_epochs - 1))
print('-' * 10)
for phase in ['train', 'valid']:
if phase == 'train':
net.train()
else:
net.eval()
running_loss = 0.0
running_corrects = 0
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs = net(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data).double()
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects / dataset_sizes[phase]
acc_history[phase].append(epoch_acc)
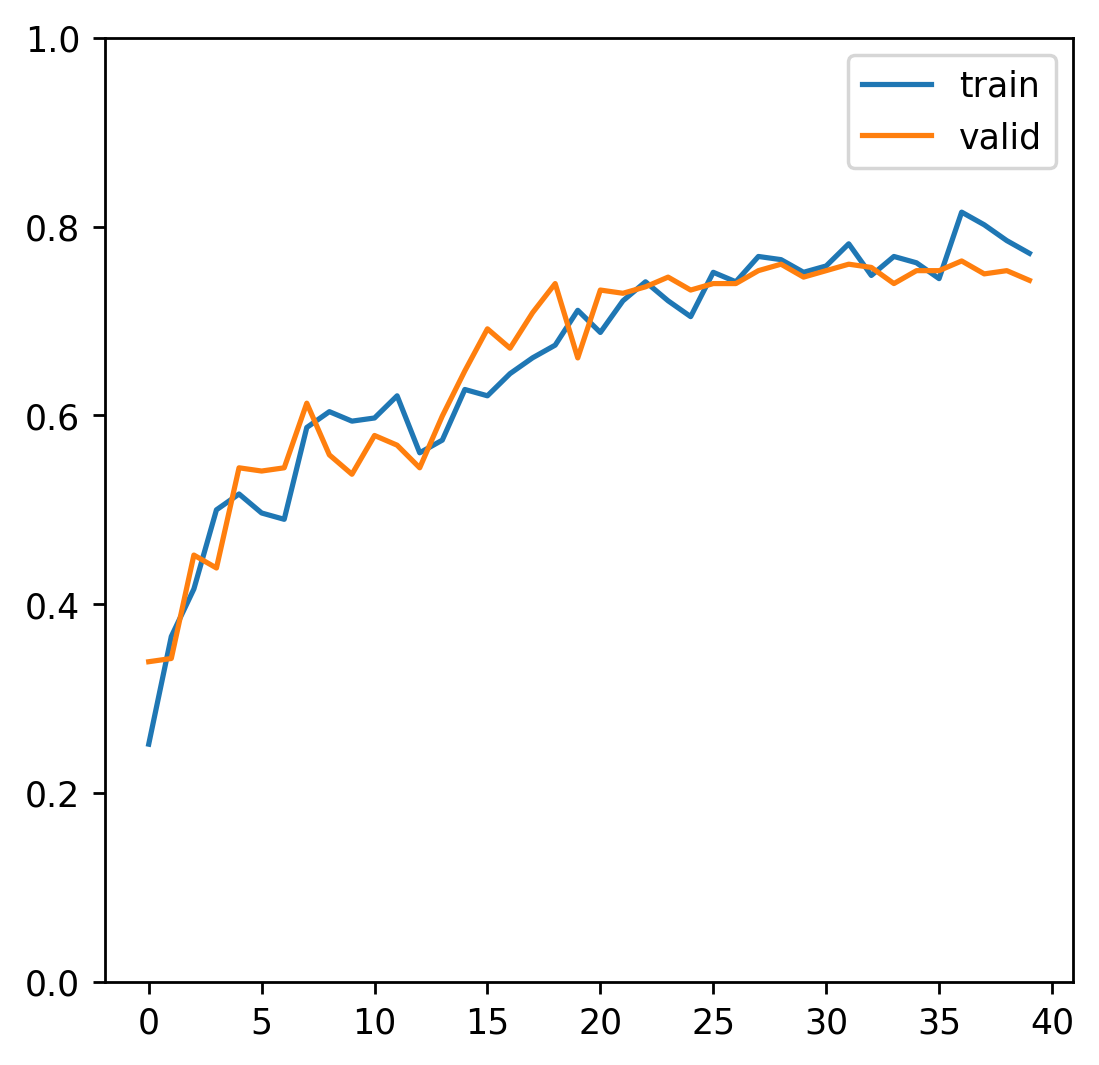
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))最後に学習精度と検証精度をグラフとして描く。
fig = plt.figure()
ax = fig.add_subplot()
ax.plot(acc_history['train'], label='train')
ax.plot(acc_history['valid'], label='valid')
ax.legend()
ax.set_ylim(0, 1)
fig.show()