ニューラルネットワークの出力層を 1 ユニットにすることで、回帰問題に利用できる。このページでは、ニューラルネットワークを使用して、複数の特徴量で、1 つの目的変数を予測する回帰問題の例を示す。
基本的なモデル定義方法と訓練の進め方
サンプルデータ
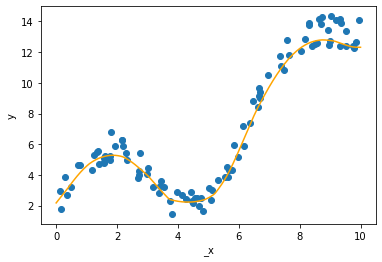
ここで乱数を使用して特徴量 x1、特徴量 x2 および教師ラベル y を作成する。x1、x2、および y の関係を示すには立体図が必要だが、このウェブページで示すには少し困難で、ここでは _x を仮の x 軸をとして可視化する。
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(2020)
_x = np.random.uniform(0, 10, 100)
x1 = np.sin(_x)
x2 = np.exp(_x / 5)
x = np.stack([x1, x2], axis=1)
y = 3 * x1 + 2 * x2 + np.random.uniform(-1, 1, 100)
fig = plt.figure()
ax = fig.add_subplot()
ax.scatter(_x, y)
ax.set_xlabel('_x')
ax.set_ylabel('y')
fig.show()
ニューラルネットワークの定義
次に、PyTorch でニューラルネットワークを定義する。ここでは、入力層 (2 unit)、中間層 (64 units)、中間層 (32 units)、および出力層 (1 unit) の 4 層からなるニューラルネットワークを定義している。
import torch
import torch.nn.functional
import torch.utils.data
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = torch.nn.Linear(2, 64)
self.fc2 = torch.nn.Linear(64, 32)
self.fc3 = torch.nn.Linear(32, 1)
def forward(self, x):
x = torch.nn.functional.relu(self.fc1(x))
x = torch.nn.functional.relu(self.fc2(x))
x = self.fc3(x)
return x
学習
上の定義に基づいてニューラルネットワークを構築し、訓練データを代入して千エポックで学習を進める。学習する際に、勾配効果法 SGD を使用して、学習率を 0.01 とする。実際のデータを解析するときは、Adam 法を利用したり、サンプル数に応じて学習率をもっと小さい値にしたりする。また、訓練時において、MSE を計算し、これを損失とする。各エポックにおける損失を epoch_loss に保存しておく。
num_epochs = 1000
x_tensor = torch.from_numpy(x).float()
y_tensor = torch.from_numpy(y.reshape(-1, 1)).float()
net = Net()
net.train()
optimizer = torch.optim.SGD(net.parameters(), lr=0.01)
criterion = torch.nn.MSELoss()
epoch_loss = []
for epoch in range(num_epochs):
outputs = net(x_tensor)
loss = criterion(outputs, y_tensor)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss.append(loss.data.numpy().tolist())訓練時における損失 epoch_loss を図示して、学習が収束具合を確認する。およそ 600 エポックぐらいで損失がほとんど減らなくなっている。
fig = plt.figure()
ax = fig.add_subplot()
ax.plot(list(range(len(epoch_loss))), epoch_loss)
ax.set_xlabel('#epoch')
ax.set_ylabel('loss')
fig.show()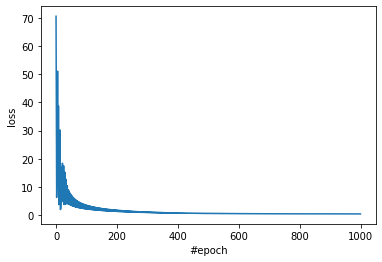
予測
次に、訓練データの上に、ニューラルネットワークで予測した回帰曲線を描き込む。
net.eval()
_x_new = np.linspace(0, 10, 1000)
x1_new = np.sin(_x_new)
x2_new = np.exp(_x_new / 5)
x_new = np.stack([x1_new, x2_new], axis=1)
x_new_tensor = torch.from_numpy(x_new).float()
with torch.no_grad():
y_pred_tensor = net(x_new_tensor)
y_pred = y_pred_tensor.data.numpy()
fig = plt.figure()
ax = fig.add_subplot()
ax.scatter(_x, y)
ax.plot(_x_new, y_pred, c='orange')
ax.set_xlabel('_x')
ax.set_ylabel('y')
fig.show()
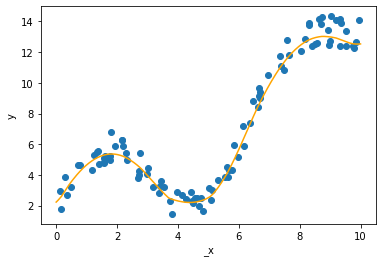
回帰曲線を見ると、ここで定義したニューラルネットワークは訓練データをうまくフィッティングできていることを確認できる。ただし、このフィッティングは訓練データに基づくものであり、訓練データの範囲外にあるデータには対応していない。つまり、_x がマイナスの時あるいは 10 を超えたときは、予測を大きく外す可能性がある。
ミニバッチ学習
データ量が多いのとき、上の例のように全サンプルを一括に使って学習を進めるのではなく、全サンプルを 32 サンプルずつに分割して、32 サンプルずつ学習を進めるミニバッチ学習がよく行われる。PyTorch でミニバッチ学習を行うために、Dataset クラスを定義する必要がある。
サンプルデータ
まず、上の例と同様に乱数で訓練データを用意する。
import numpy as np
np.random.seed(2020)
_x = np.random.uniform(0, 10, 100)
x1 = np.sin(_x)
x2 = np.exp(_x / 5)
x = np.stack([x1, x2], axis=1)
y = 3 * x1 + 2 * x2 + np.random.uniform(-1, 1, 100)Dataset クラスの定義
Dataset クラスを定義する。このクラスを定義するとき、torch.utils.data.Dataset クラスを継承する必要がある。また、最低限に __len__ と __getitem__ メソッドを定義する必要がある。__len__ は、訓練サンプルの全サンプル数を返すメソッドをである。また、__getitem__ は i 番目の訓練サンプルを返すメソッドである。また、テストデータの場合は y が存在しない時があるので、それを考慮して設計する。次は、Dataset クラスを MakeDataset の名前で定義する例を示している。
import torch
import torch
class MakeDataset(torch.utils.data.Dataset):
def __init__(self, x, y=None):
self.x = x
self.y = y
def __len__(self):
return self.x.shape[0]
def __getitem__(self, i):
x = torch.from_numpy(self.x[i]).float()
if self.y is not None:
y = torch.from_numpy(self.y[i]).float()
if self.y is not None:
return x, y
else:
return x深層学習では本来はデータ量が大きく、データをすべてメモリ上に保存できない。そのため、この Dataset クラスを定義して、データを 1 つだけ読み取って、返すように設計する必要がある。例えば、画像を 1 万枚あるとき、その 1 万枚の画像のパスをテキストファイルに書き込み、Dataset クラスにそのテキストファイルのパスを入力する、そして、__getitem__ 関数で、引数 i が与えられたら、そのテキストファイル中の i 番目の画像を読み込み、その画像の行列データを返すように Dataset クラスを設計する。
ここではミニバッチ学習の簡単な例を示すために、全データをあらかじめ読み込んでから、 Dataset クラスに代入しているという非適切な使い方をしている。
ニューラルネットワークの定義
ニューラルネットワークを定義する。上と同様に、入力層 (2 unit)、中間層 (64 units)、中間層 (32 units)、および出力層 (1 unit) の 4 層からなるニューラルネットワークとする。
import torch
import torch.nn.functional
import torch.utils.data
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = torch.nn.Linear(2, 64)
self.fc2 = torch.nn.Linear(64, 32)
self.fc3 = torch.nn.Linear(32, 1)
def forward(self, x):
x = torch.nn.functional.relu(self.fc1(x))
x = torch.nn.functional.relu(self.fc2(x))
x = self.fc3(x)
return xミニバッチ学習
Dataset クラスを準備したのち、サンプルデータセットを Dataset クラス(MakeDataset)に代入し、インスタンスを生成する。次に、このインスタンスを PyTorch の DataLoader クラスに代入し、ミニバッチ用のイテレーターを用意する。DataLoader を使用する時、入力データをシャッフルするかどうか、またバッチサイズを指定する必要がある。
num_epochs = 1000
batch_size = 64
# prepare dataset
dataset = MakeDataset(x, y.reshape(-1, 1))
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)
# prepare model and training parameters
net = Net()
net.train()
optimizer = torch.optim.SGD(net.parameters(), lr=0.01)
criterion = torch.nn.MSELoss()
# training
epoch_loss = []
for epoch in range(num_epochs):
# use 'dataloader' to start batch learning
running_loss = 0 # loss in this epoch
for inputs, labels in dataloader:
outputs = net(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# add loss of this batch to loss of epoch
running_loss += loss.data.numpy().tolist()
epoch_loss.append(running_loss)予測
予測時もミニバッチで行うことができる。ここでテストデータを作成して、上で学習したモデルにで予測を行ってみる。
net.eval()
_x_new = np.linspace(0, 10, 1000)
x1_new = np.sin(_x_new)
x2_new = np.exp(_x_new / 5)
x_new = np.stack([x1_new, x2_new], axis=1)
test_dataset = MakeDataset(x_new)
dataloader = torch.utils.data.DataLoader(test_dataset, batch_size=64)
y_pred = None
with torch.no_grad():
for inputs in dataloader:
outputs = net(inputs)
if y_pred is None:
y_pred = outputs.data.numpy()
else:
y_pred = np.concatenate([y_pred, outputs.data.numpy()])
y_pred = y_pred.reshape(-1)
fig = plt.figure()
ax = fig.add_subplot()
ax.scatter(_x, y)
ax.plot(_x_new, y_pred, c='orange')
ax.set_xlabel('_x')
ax.set_ylabel('y')
fig.show()