VGG16 は、深層学習のブレークアウト初期に発表され、画像分類を行う畳み込みニューラルネットワーク(CNN)の一つである。VGG16 は畳み込み層、プーリング層、および全結合層からなる非常に単純なアーキテクチャからなる。このページでは、PyTroch の基本的な関数を使用して、VGG16 のアーキテクチャを構築し、学習と検証を行う例を示す。まず、このページで必要なパッケージを呼び出して準備する。
import os
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
from torchvision import modelstorchvision の VGG16 アーキテクチャ
PyTorch を開発している団体から torchvision と呼ばれるパッケージも開発されている。torchvision のパッケージには、有名な画像判別アーキテクチャがすでに構築されて、簡単に利用できる状態で用意されている。ここで、torchvision で定義されている VGG16 のアーキテクチャを実際に出力してみることにする。ここで出力されている各層の特徴を参考にして、このネットワークをゼロか構築してくことにする。
pytorch_vgg16 = models.vgg16(pretrained=False)
print(pytorch_vgg16)
## VGG(
## (features): Sequential(
## (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
## (1): ReLU(inplace=True)
## (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
## (3): ReLU(inplace=True)
## (4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
## (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
## (6): ReLU(inplace=True)
## (7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
## (8): ReLU(inplace=True)
## (9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
## (10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
## (11): ReLU(inplace=True)
## (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
## (13): ReLU(inplace=True)
## (14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
## (15): ReLU(inplace=True)
## (16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
## (17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
## (18): ReLU(inplace=True)
## (19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
## (20): ReLU(inplace=True)
## (21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
## (22): ReLU(inplace=True)
## (23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
## (24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
## (25): ReLU(inplace=True)
## (26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
## (27): ReLU(inplace=True)
## (28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
## (29): ReLU(inplace=True)
## (30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
## )
## (avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
## (classifier): Sequential(
## (0): Linear(in_features=25088, out_features=4096, bias=True)
## (1): ReLU(inplace=True)
## (2): Dropout(p=0.5, inplace=False)
## (3): Linear(in_features=4096, out_features=4096, bias=True)
## (4): ReLU(inplace=True)
## (5): Dropout(p=0.5, inplace=False)
## (6): Linear(in_features=4096, out_features=1000, bias=True)
## )
## )VGG16 アーキテクチャの設計
VGG16 のアーキテクチャは、「畳み込み層・畳み込み層・プーリング層」というブロックを 2 回繰り返し、「畳み込み層・畳み込み層・畳み込み層・プーリング層」というブロックを 3 回繰り返して、最後に 3 層の全結合層が続く形になっている(Simonyan et al., 2014)。上で確認したように、 torchvision パッケージで用意されている VGG16 のアーキテクチャもこの構造となっている。
この VGG16 のアーキテクチャを構築してみる。設計書を実際に確認してみる。
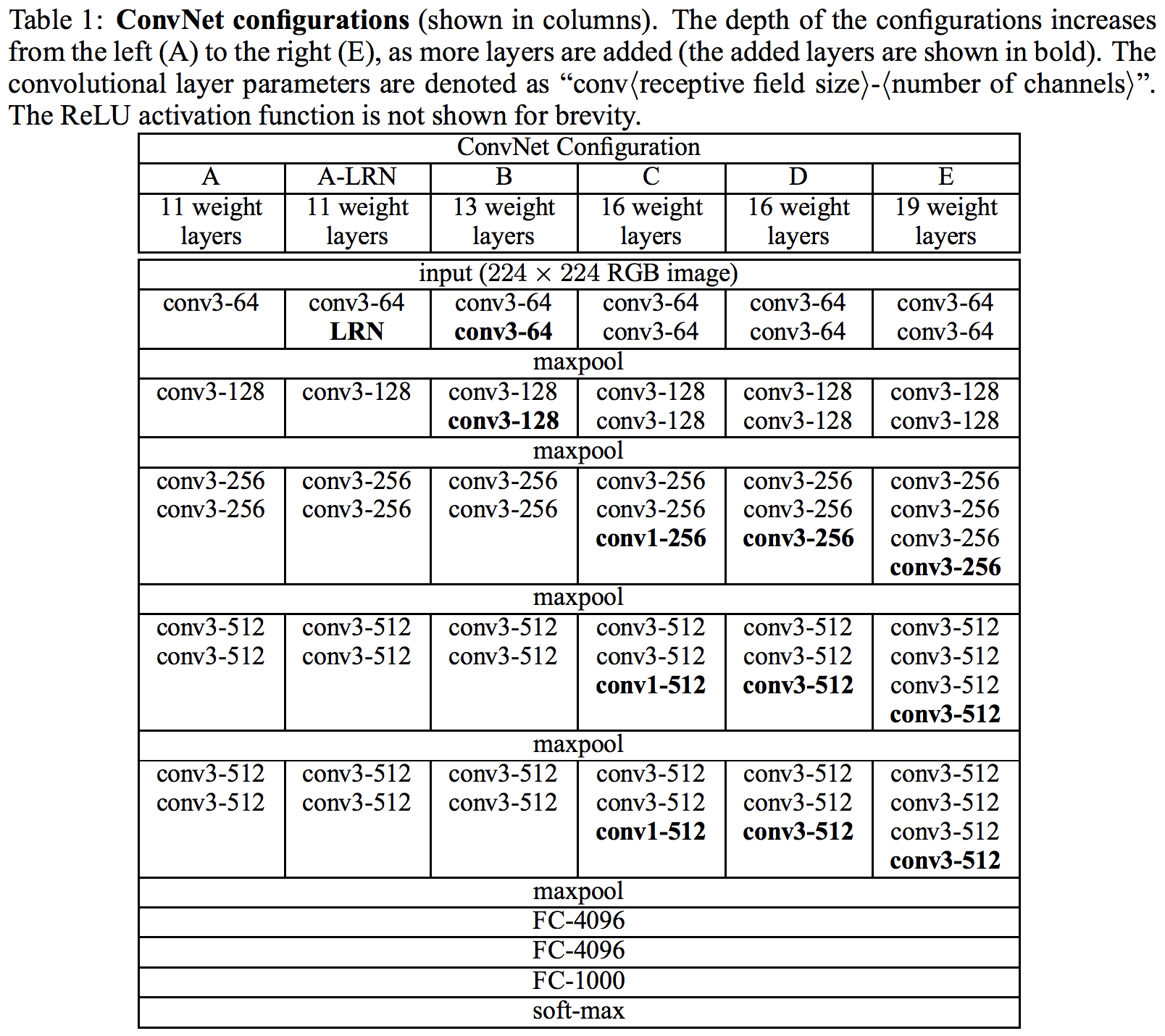
PyTorch でネットワークのアーキテクチャを定義するときは、クラスとして定義する。クラスの名前は任意につけることができる。下の例では myVGG としている。また、Pytorch でアーキテクチャを構築する際に、まず、ネットワークに必要な部品を作成し、次に各部品をつなげていく、という手順をとる。VGG16 に必要な必要な部品は、上で確認したように、「畳み込み層・畳み込み層・プーリング層」というブロックが 2 つ、「畳み込み層・畳み込み層・畳み込み層・プーリング層」というブロックが 3 つ、そして、全結合層が 3 つである。まず、これらの部品の定義を __init__ 関数の中で定義する。部品を定義してから、次に forward 関数の中で各部品をつなげていく。ここで書き上げたクラスが、ネットワークのアーキテクチャの設計図のようなものとなる。
class myVGG(nn.Module):
def __init__(self):
super(myVGG, self).__init__()
self.conv01 = nn.Conv2d(3, 64, 3)
self.conv02 = nn.Conv2d(64, 64, 3)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv03 = nn.Conv2d(64, 128, 3)
self.conv04 = nn.Conv2d(128, 128, 3)
self.pool2 = nn.MaxPool2d(2, 2)
self.conv05 = nn.Conv2d(128, 256, 3)
self.conv06 = nn.Conv2d(256, 256, 3)
self.conv07 = nn.Conv2d(256, 256, 3)
self.pool3 = nn.MaxPool2d(2, 2)
self.conv08 = nn.Conv2d(256, 512, 3)
self.conv09 = nn.Conv2d(512, 512, 3)
self.conv10 = nn.Conv2d(512, 512, 3)
self.pool4 = nn.MaxPool2d(2, 2)
self.conv11 = nn.Conv2d(512, 512, 3)
self.conv12 = nn.Conv2d(512, 512, 3)
self.conv13 = nn.Conv2d(512, 512, 3)
self.pool5 = nn.MaxPool2d(2, 2)
self.avepool1 = nn.AdaptiveAvgPool2d((7, 7))
self.fc1 = nn.Linear(512 * 7 * 7, 4096)
self.fc2 = nn.Linear(4096, 4096)
self.fc3 = nn.Linear(4096, 5)
self.dropout1 = nn.Dropout(0.5)
self.dropout2 = nn.Dropout(0.5)
def forward(self, x):
x = F.relu(self.conv01(x))
x = F.relu(self.conv02(x))
x = self.pool1(x)
x = F.relu(self.conv03(x))
x = F.relu(self.conv04(x))
x = self.pool2(x)
x = F.relu(self.conv05(x))
x = F.relu(self.conv06(x))
x = F.relu(self.conv07(x))
x = self.pool3(x)
x = F.relu(self.conv08(x))
x = F.relu(self.conv09(x))
x = F.relu(self.conv10(x))
x = self.pool4(x)
x = F.relu(self.conv11(x))
x = F.relu(self.conv12(x))
x = F.relu(self.conv13(x))
x = self.pool5(x)
x = self.avepool1(x)
# 行列をベクトルに変換
x = x.view(-1, 512 * 7 * 7)
x = F.relu(self.fc1(x))
x = self.dropout1(x)
x = F.relu(self.fc2(x))
x = self.dropout2(x)
x = self.fc3(x)
return x次に、上の設計図から実体を作り出してみる。
net = myVGG()
print(net)
## myVGG(
## (conv01): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1))
## (conv02): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
## (pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
## (conv03): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1))
## (conv04): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1))
## (pool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
## (conv05): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1))
## (conv06): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
## (conv07): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
## (pool3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
## (conv08): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1))
## (conv09): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1))
## (conv10): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1))
## (pool4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
## (conv11): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1))
## (conv12): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1))
## (conv13): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1))
## (pool5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
## (avepool1): AdaptiveAvgPool2d(output_size=(7, 7))
## (fc1): Linear(in_features=25088, out_features=4096, bias=True)
## (fc2): Linear(in_features=4096, out_features=4096, bias=True)
## (fc3): Linear(in_features=4096, out_features=5, bias=True)
## (dropout1): Dropout(p=0.5, inplace=False)
## (dropout2): Dropout(p=0.5, inplace=False)
## )データの準備
ここでは PlantVillage の画像をサンプルデータとして使う。ただし、オリジナルのデータセットのサイズが非常に大きいため、ここでは枚数を減らした小さいデータセットを使うことにする。まず、訓練データと検証データを読み込み、準備を行う。
transform_train = torchvision.transforms.Compose([
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
transform_valid = torchvision.transforms.Compose([
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_data_dir = 'plantvillage/image/train'
valid_data_dir = 'plantvillage/image/valid'
# training set
trainset = torchvision.datasets.ImageFolder(train_data_dir, transform=transform_train)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=16, shuffle=True)
# validation set
validset = torchvision.datasets.ImageFolder(valid_data_dir, transform=transform_valid)
validloader = torch.utils.data.DataLoader(validset, batch_size=16, shuffle=False)モデルの学習
以上の作業で、VGG16 モデルを作成し、データの読み込みが完了した。続けて、モデルを GPU 上に送り、訓練モードに切り替える。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net.to(device)
net.train()ここからモデルを学習させる。まず、損失関数として交差エントロピー関数を使用し、学習アルゴリズムを Adam 法を使用する。まず、学習率を 0.00001 として、50 エポック分学習させる。VGG16 のパラメーター数が非常に多いため、データの枚数やデータの種類(複雑さ)によって、学習が進まない場合がある。その際に、さまざま学習率を試して、最適なものを選ぶ。ここでは、0.1, 0.01, 0.001, 0.0001, 0.00001 などを試して、最終的に 0.00001 を決めた。
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.00001)
# 同じデータを 50 回学習します
for epoch in range(50):
# 今回の学習効果を保存するための変数
running_loss = 0.0
for data in trainloader:
# データ整理
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
# 前回の勾配情報をリセット
optimizer.zero_grad()
# 予測
outputs = net(inputs)
# 予測結果と教師ラベルを比べて損失を計算
loss = criterion(outputs, labels)
running_loss += loss.item()
# 損失に基づいてネットワークのパラメーターを更新
loss.backward()
optimizer.step()
# このエポックの学習効果
print(running_loss)続けて、学習率を 0.1 倍にしてさらに 50 エポック学習する。
optimizer = optim.Adam(net.parameters(), lr=0.000001)
for epoch in range(50):
running_loss = 0.0
for data in trainloader:
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
running_loss += loss.item()
loss.backward()
optimizer.step()
print(running_loss)一定のエポックごとに学習率を小さくすると、学習が比較的に進みやすい。上の例では、コードをコピー&ペーストで学習率の変更と再学習を進めているが、PyTroch のスケジューラー機能を使うと、学習時に、学習率を自動的に小さくすることができる。スケジューラーの使い方について、torch.optim.lr_scheduler を参考のこと。
モデルの検証
学習を終えたモデルに、検証データ代入して、予測精度を検証する。
# モデルを評価モードにする
net.eval()
# 全検証データの正しく分類できた枚数を記録
n_correct = 0
n_total = 0
for data in validloader:
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
# 予測
outputs = net(inputs)
# 予測結果をクラス番号に変換
_, predicted = torch.max(outputs.data, 1)
# 予測結果と実際のラベルを比較して、正しく予測できた枚数を計算
res = (predicted == labels)
res = res.sum().item()
# 今までに正しく予測できた枚数に計上
n_correct = n_correct + res
n_total = n_total + len(labels)
print(n_correct / n_total)
## 0.636986301369863References
- Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv. 2014. arXiv: 1409.1556