torchvision パッケージには VGG や ResNet などのような有名なアーキテクチャが実装されている。また、これらのアーキテクチャを ImageNet データセットで学習させた重みも用意されている。学習済みのアーキテクチャを利用して、自分たちのデータセットで再学習させることで、学習時間を大きく短縮させることができる。また、場合によって、精度の向上も期待できる。このように、あるデータセットを使って学習させたモデルに、別のデータセットを与えて再学習させることを転移学習やファインチューニングと読んだりする。このページでは、転移学習・ファインチューニングの進め方を示す。
<p>必要なパッケージ群を読み込む。matplotlib は学習精度をグラフとして可視化する時に利用する。torch および torchvision は物体分類用のモデルを作成する際に利用する。
import matplotlib.pyplot as plt
import torch
import torchvision学習用画像および検証用画像を、PyTorch の ImageFolder 関数で読み込めるようなフォルダ構造になるように整理する。ここでは PlantVillage 画像データの一部(ダウンロード)を使う。
data_transforms = {
'train': torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(224),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'valid': torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
train_data_dir = 'drive/My Drive/datasets/plantvillage/train'
valid_data_dir = 'drive/My Drive/datasets/plantvillage/valid'
image_datasets = {
'train': torchvision.datasets.ImageFolder(train_data_dir, transform=data_transforms['train']),
'valid': torchvision.datasets.ImageFolder(valid_data_dir, transform=data_transforms['valid'])
}
dataloaders = {
'train': torch.utils.data.DataLoader(image_datasets['train'], batch_size=16, shuffle=True),
'valid': torch.utils.data.DataLoader(image_datasets['valid'], batch_size=16)
}
dataset_sizes = {
'train': len(image_datasets['train']),
'valid': len(image_datasets['valid'])
}
class_names = image_datasets['train'].classes
## c_0 c_1 c_2 c_3 c_4転移学習(例1)
転移学習を行う例を示す。ここでは、ImageNet で学習させた VGG16 のアーキテクチャと重みを torchvision パッケージから読み込む。既存の VGG16 の出力層は 1000 カテゴリであるので、この出力層を PlantVillage サンプルデータのカテゴリ数(len(class_names) に修正する。その後、損失関数および学習パラメーターを定義し、学習の準備を整える。
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 出力層の変更
net_ft1 = torchvision.models.vgg16(pretrained=True)
num_ftrs = net_ft1.classifier[6].in_features
net_ft1.classifier[6] = torch.nn.Linear(num_ftrs, len(class_names))
net_ft1 = net_ft1.to(device)
# 損失関数および学習パラメーターの定義
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net_ft1.parameters(), lr=0.001, momentum=0.9)
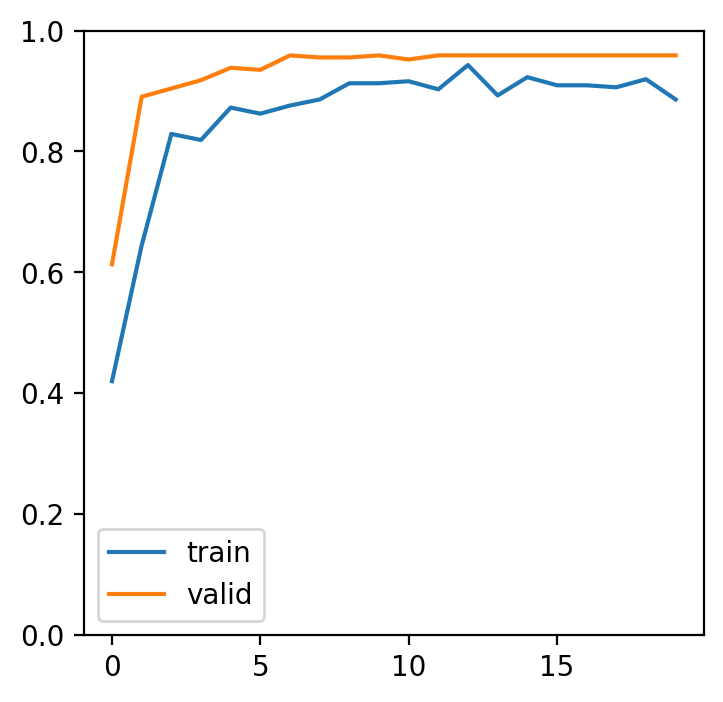
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)転移学習は、初期状態からの学習に比べて、より少ない学習回数で収束することが多い。例えば、初期状態から学習する場合、40 エポックの学習を行っても、学習精度(訓練精度)が 70% ほどである(実施例)。これに比べて、転移学習の場合は、以下のように 20 エポックの学習を行うだけで、学習精度が 99% 前後になる。
num_epochs = 20
acc_history_ft1 = {'train': [], 'valid': []}
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
for phase in ['train', 'valid']:
if phase == 'train':
net_ft1.train()
else:
net_ft1.eval()
running_loss = 0.0
running_corrects = 0
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs = net_ft1(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
acc_history_ft1[phase].append(epoch_acc)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))fig = plt.figure(figsize=(4,4),dpi=200)
ax = fig.add_subplot()
ax.plot(acc_history_ft1['train'], label='train')
ax.plot(acc_history_ft1['valid'], label='valid')
ax.legend()
ax.set_ylim(0, 1)
fig.show()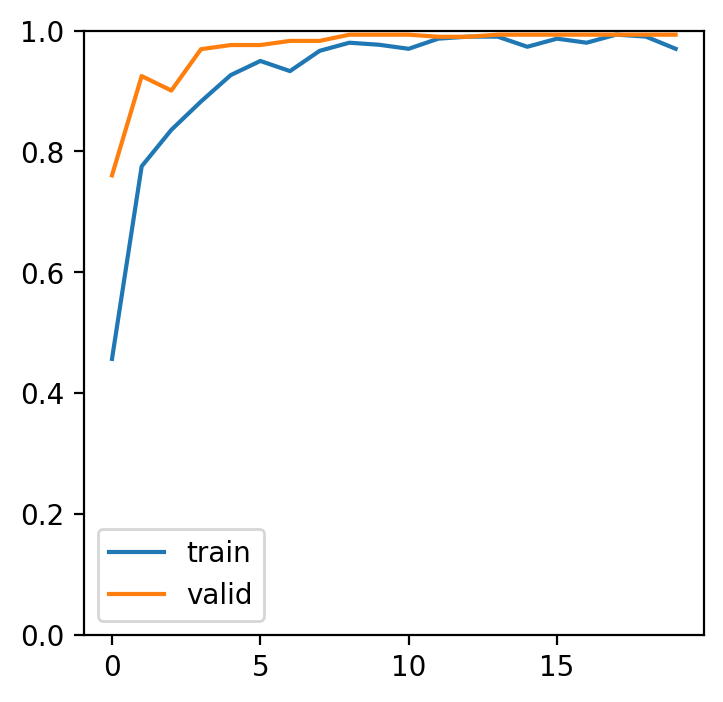
転移学習(例2)
上と異なる学習例を示す。VGG16 のモデル構造は、特徴抽出を行う畳み込み層(features、avgpool)と分類を行う全結合層(classifier)の 2 つの部分からなる。上に示した転移学習では、畳み込み層と全結合層のパラメータ全体を再学習させていた。ここでは、畳み込み層のパラメータを固定させて学習できないようにし、全結合層のパラメータのみを再学習させてみる。
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
net_ft2 = torchvision.models.vgg16(pretrained=True)
num_ftrs = net_ft2.classifier[6].in_features
net_ft2.classifier[6] = torch.nn.Linear(num_ftrs, len(class_names))
# 畳み込み層(features, avgpool)部分のパラメーターを固定
for param in net_ft2.features.parameters():
param.requires_grad = False
for param in net_ft2.avgpool.parameters():
param.requires_grad = Falseパラメータの固定を行った後は、上と同様にして、損失関数と学習パラメータを定義し、学習を進める。
net_ft2 = net_ft2.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net_ft2.parameters(), lr=0.001, momentum=0.9)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)num_epochs = 20
acc_history_ft2 = {'train': [], 'valid': []}
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
for phase in ['train', 'valid']:
if phase == 'train':
net_ft2.train()
else:
net_ft2.eval()
running_loss = 0.0
running_corrects = 0
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs = net_ft2(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
acc_history_ft2[phase].append(epoch_acc)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))fig = plt.figure(figsize=(4,4),dpi=200)
ax = fig.add_subplot()
ax.plot(acc_history_ft1['train'], label='train')
ax.plot(acc_history_ft1['valid'], label='valid')
ax.legend()
ax.set_ylim(0, 1)
fig.show()