畳み込みニューラルネットワークの各層を可視化する方法のなかで Grad-CAM が比較的によく知られている。この Grad-CAM を拡張した方法として GradCAM++、Guided Grad-CAM などが多数発表されている。この中で Guided Grad-CAM は Grad-CAM と guided backpropagation の両者の結果を重ね合わせたものである。このページでは、GitHub jacobgil/pytorch-grad-cam で公開されているコードを使って、PyTorch で構築した畳み込みニューラルネットワークに Guided Grad-CAM を適用する方法を紹介する。
Guided Grad-CAM は、最後の畳み込み層の出力を使用して計算する。そこで、訓練済みのモデルに画像を代入して、モデルの各層を少しずつ実行していき、最後の畳み込み層の結果をいったん変数に保存する必要がある。また、Guided Grad-CAM の一部である guided backpropagation 処理を行う際に、モデルの重みが書き換えられる。そのため、Guided Grad-CAM を実行するときにモデルそのものに対して実行するのではなく、モデルのコピーを一つ作って、そのコピーを利用して Guided Grad-CAM を計算したほうがいい。以下に、VGG16 および ResNet18 のモデル(アーキテクチャ)に Grad-CAM を適用する方法を示す。
VGG16
PyTorch で構築された(あるいは転移学習を行ったあとの) VGG16 のモデルに Grad-CAM を適用する方法を示す。モデルの訓練から Grad-CAM までの流れを示した全コードは ![]() を参照のこと。ここでは、訓練済みのモデルがすでに用意されて、
を参照のこと。ここでは、訓練済みのモデルがすでに用意されて、nent_ft という変数に保存されているものとする。まず、net_ft のアーキテクチャを出力して、各層の構造を確認する。
print(net_ft)
# VGG(
# (features): Sequential(
# (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (1): ReLU(inplace=True)
# (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (3): ReLU(inplace=True)
# (4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (6): ReLU(inplace=True)
# (7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (8): ReLU(inplace=True)
# (9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (11): ReLU(inplace=True)
# (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (13): ReLU(inplace=True)
# (14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (15): ReLU(inplace=True)
# (16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (18): ReLU(inplace=True)
# (19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (20): ReLU(inplace=True)
# (21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (22): ReLU(inplace=True)
# (23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (25): ReLU(inplace=True)
# (26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (27): ReLU(inplace=True)
# (28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (29): ReLU(inplace=True)
# (30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# )
# (avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
# (classifier): Sequential(
# (0): Linear(in_features=25088, out_features=4096, bias=True)
# (1): ReLU(inplace=True)
# (2): Dropout(p=0.5, inplace=False)
# (3): Linear(in_features=4096, out_features=4096, bias=True)
# (4): ReLU(inplace=True)
# (5): Dropout(p=0.5, inplace=False)
# (6): Linear(in_features=4096, out_features=5, bias=True)
# )
# )出力された VGG16 のアーキテクチャを確認すると、VGG16 は features、avgpool、classifier という 3 つのレイヤーのまとまり(モジュール)からなる。最後の畳み込み層の出力は features モジュールの第 29 層((29): ReLU(inplace=True))の出力である。そこで、VGG16 モデルに画像を代入して、features モジュールの第 29 層までいったん実行して、その出力値を変数に保存する。
この処理を行うクラスなどを定義する。コードが長くなるので、詳細は ![]() にある
にある GuidedBackpropReLUModel、GuidedBackpropReLU、GradCam、ModelOutputs、FeatureExtractor の定義を確認してください。これらのクラスを定義した後に、
grad_cam = GradCam(model=copy.deepcopy(net_ft), feature_module=model.features, \
target_layer_names=['29'], use_cuda=True)のように呼び出すと、Grad-CAM と guided backpropagation を計算できるようになり、最後に両者を重ね合わせればよい。実際にこの処理を行なっているのが ![]() にある
にある preprocess_image 関数である。
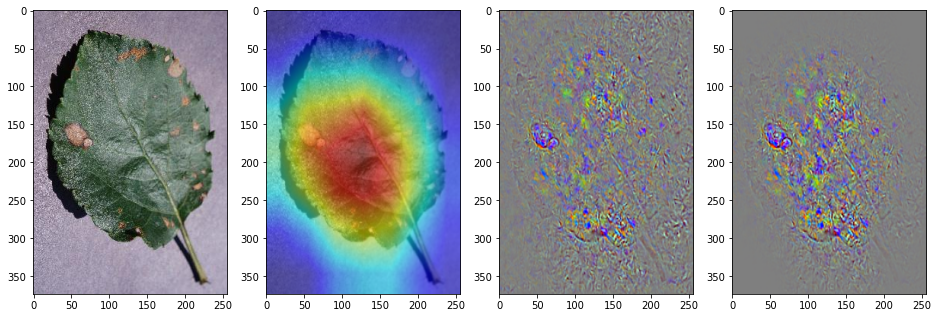
実際に実行した結果が次のようになる。左からオリジナル画像、Grad-CAM、guided backpropagation、そして Guided Grad-CAM である。
img = '/path/to/image.jpg'
img_gradcam = get_gradcam_image(net_ft, img)
plt.figure(figsize=(16,12))
plt.subplot(1, 4, 1)
plt.imshow(cv2.cvtColor(cv2.imread(img, 1), cv2.COLOR_BGR2RGB))
plt.subplot(1, 4, 2)
plt.imshow(cv2.cvtColor(img_gradcam[0], cv2.COLOR_BGR2RGB))
plt.subplot(1, 4, 3)
plt.imshow(cv2.cvtColor(img_gradcam[1], cv2.COLOR_BGR2RGB))
plt.subplot(1, 4, 4)
plt.imshow(cv2.cvtColor(img_gradcam[2], cv2.COLOR_BGR2RGB))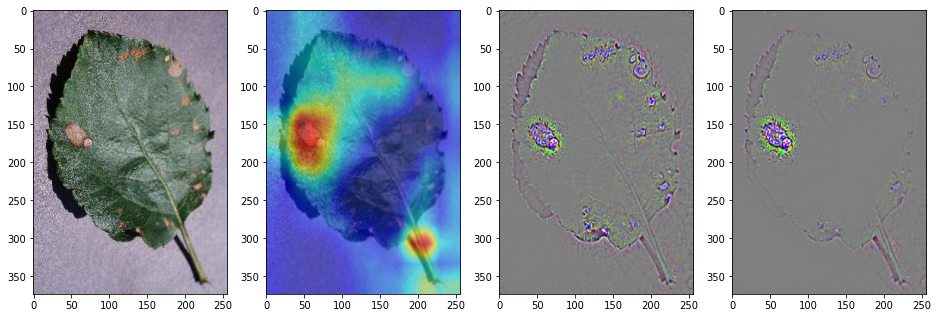
ResNet18
ResNet18 でも同様に Guided Grad-CAM を計算できる。ここで、訓練済みの ResNet18 のオブジェクト net_ft の構造を確認してみる。
print(net_ft)
# ResNet(
# (conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
# (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
# (layer1): Sequential(
# (0): BasicBlock(
# (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
# (1): BasicBlock(
# (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
# )
# (layer2): Sequential(
# (0): BasicBlock(
# (conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (downsample): Sequential(
# (0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
# (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
# )
# (1): BasicBlock(
# (conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
# )
# (layer3): Sequential(
# (0): BasicBlock(
# (conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (downsample): Sequential(
# (0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
# (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
# )
# (1): BasicBlock(
# (conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
# )
# (layer4): Sequential(
# (0): BasicBlock(
# (conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (downsample): Sequential(
# (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
# (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
# )
# (1): BasicBlock(
# (conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
# )
# (avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
# (fc): Linear(in_features=512, out_features=5, bias=True)
# )ResNet18 は、residue block とよばれるモジュールが複数重ねられて作られたアーキテクチャである。そのため、ResNet18 のアーキテクチャは、畳み込み層やプーリング層を単純に重ねただけの VGG16 よりも複雑に見える。ResNet18 のモジュールを確認すると、conv1、bn1、relu、maxpool、layer1、layer2、layer3、layer4、avgpool、fc のように並んでいる。最後の畳み込み層の出力は、layer4 の (1) の出力値である。そこで、ResNet18 モデルに画像を代入して、layer4 (1) 層を対象に Guided Grad-CAM を計算してみる。
grad_cam = GradCam(model=model, feature_module=model.layer4, \
target_layer_names=['1'], use_cuda=True)ResNet18 に対して Guided Grad-CAM を実行した結果をみると次のようになっている。なお、詳細なコードは ![]() を参照してください。
を参照してください。