深層学習のアーキテクチャは膨大な量のパラメータを持つ。これらのパラメータを適度に学習させるためには、大量な画像データを用意する必要がある。アーキテクチャの学習時に入力される画像は、RGB の行列に変換されてからそのまま学習に用いられる。そのため学習済みのアーキテクチャ(モデル)は、学習データの影響を強く受け継いでいる可能性ある。例えば、学習画像に含まれる車の写真がほとんど左側面から撮影されたものであれば、その学習済みのモデルに右側面から撮影した車の写真を入力しても、うまく予測できない場合がある。このとき、学習を行う際に、入力画像をランダムに左右反転させることで、そのアーキテクチャは、見かけ上、左側面と右側面の車の両方を学習できるようになり、汎化性能が高くなると考えられる。
学習時に既存の学習用画像を反転させたり、画像にノイズやぼかしを加えたりして、画像のデータを増やす操作を data augmentation とよぶ。適切な data augmentation を行うことで、モデルの汎化性能を高めることができる。しかし、data augmentation の方法や目的によっては、汎化性能の向上しないこともしばしばある。例えば。車の側面を撮影した写真を data augmentation を行いながら学習させたモデルがあったとする。そのモデルに、ドローンで撮影した投影図を入力しても、車を検出できないと考えられる。これは、そもそも元データの中に車の投影写真がないから、車の側面写真をどんなに data augmentation を行なっていても、車の投影画像を作り出せないからである。したがって、data augmentation を行うのにあたって、使用目的に応じた augmentation を行う必要がある。
data augmentation を行う方法は様々ある。自分で OpenCV、 scikit-image や GAN などを使って、既存画像に対して augmentation を行い、その画像をあとで学習に用いる。あるいは、学習を行うとき、画像データを読み込んだ直後に augmentation 操作を行う。後者の場合は imgaug などのパッケージがある。このページでは imgaug の使い方を示す。
まず、必要なパッケージ群を読み込む。matplotlib は学習精度をグラフとして可視化する時に利用する。torch および torchvision は物体分類用のモデルを作成する際に利用する。
import matplotlib.pyplot as plt
import torch
import torchvision
import imgaug as ia次に学習用画像および検証用画像を、PyTorch の ImageFolder 関数で読み込めるようなフォルダ構造になるように整理する。ここでは PlantVillage 画像データの一部(ダウンロード)を使う。
画像の読み込み直後に imgaug パッケージで data augmentation を行うために、これらの操作をクラスとして定義する。
class ImgaugTransform:
def __init__(self):
self.aug = ia.augmenters.Sequential([
ia.augmenters.Resize((224, 224)),
ia.augmenters.Sometimes(0.1, ia.augmenters.Add((-40, 40))),
ia.augmenters.Sometimes(0.1, ia.augmenters.AdditiveGaussianNoise(scale=(0, 0.2*255))),
ia.augmenters.Sometimes(0.1, ia.augmenters.GaussianBlur(sigma=(0, 3.0))),
ia.augmenters.Fliplr(0.5),
ia.augmenters.Affine(rotate=(-20, 20), mode='symmetric'),
ia.augmenters.Sometimes(0.1,
ia.augmenters.OneOf([ia.augmenters.Dropout(p=(0, 0.1)),
ia.augmenters.CoarseDropout(0.1, size_percent=0.5)])),
ia.augmenters.Cutout(nb_iterations=(1, 5), size=0.2, squared=False, fill_mode='gaussian', fill_per_channel=True),
ia.augmenters.AddToHueAndSaturation(value=(-10, 10), per_channel=True)
])
def __call__(self, img):
img = np.array(img)
return self.aug.augment_image(img)ここで定義した操作を使って、画像を読み込んだ後に augmentation するようにコードを書く。
imgaug_transform = ImgaugTransform()
data_transforms = {
'train': torchvision.transforms.Compose([
torchvision.transforms.Lambda(lambda x: imgaug_transform(x)),
torchvision.transforms.ToPILImage(),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'valid': torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
train_data_dir = 'drive/My Drive/datasets/plantvillage/train'
valid_data_dir = 'drive/My Drive/datasets/plantvillage/valid'
image_datasets = {
'train': torchvision.datasets.ImageFolder(train_data_dir, transform=data_transforms['train']),
'valid': torchvision.datasets.ImageFolder(valid_data_dir, transform=data_transforms['valid'])
}
dataloaders = {
'train': torch.utils.data.DataLoader(image_datasets['train'], batch_size=16, shuffle=True),
'valid': torch.utils.data.DataLoader(image_datasets['valid'], batch_size=16)
}
dataset_sizes = {
'train': len(image_datasets['train']),
'valid': len(image_datasets['valid'])
}
class_names = image_datasets['train'].classes
print(class_names)
## c_0 c_1 c_2 c_3 c_4続けて、torchvision に実装されている VGG16 のアーキテクチャを呼び出して、その出力層を 5 (len(class_names))カテゴリとなるように変更する。その後、そのモデルを GPU 上に送る。
net = torchvision.models.vgg16(pretrained=False)
num_ftrs = net.classifier[6].in_features
net.classifier[6] = torch.nn.Linear(num_ftrs, len(class_names))
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
net = net.to(device)損失関数および学習アルゴリズムなどを定義する。このページで使っているサンプルデータは難しいデータなので、学習率とスケジューラの調整が非常に難しい。数時間調整した結果、結局次のようなパラメーターである程度うまくいくことがわかった。
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.00005)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.1)上で定義したデータおよびアルゴリズムなどを使用して、学習と検証を繰り返す。また、各エポックにおいて学習精度と検証精度を記録しておく。
num_epochs = 40
acc_history = {'train': [], 'valid': []}
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch + 1, num_epochs - 1))
print('-' * 10)
for phase in ['train', 'valid']:
if phase == 'train':
net.train()
else:
net.eval()
running_loss = 0.0
running_corrects = 0
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs = net(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data).double()
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects / dataset_sizes[phase]
acc_history[phase].append(epoch_acc)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))最後に学習精度と検証精度をグラフとして描く。
fig = plt.figure()
ax = fig.add_subplot()
ax.plot(acc_history['train'], label='train')
ax.plot(acc_history['valid'], label='valid')
ax.legend()
ax.set_ylim(0, 1)
fig.show()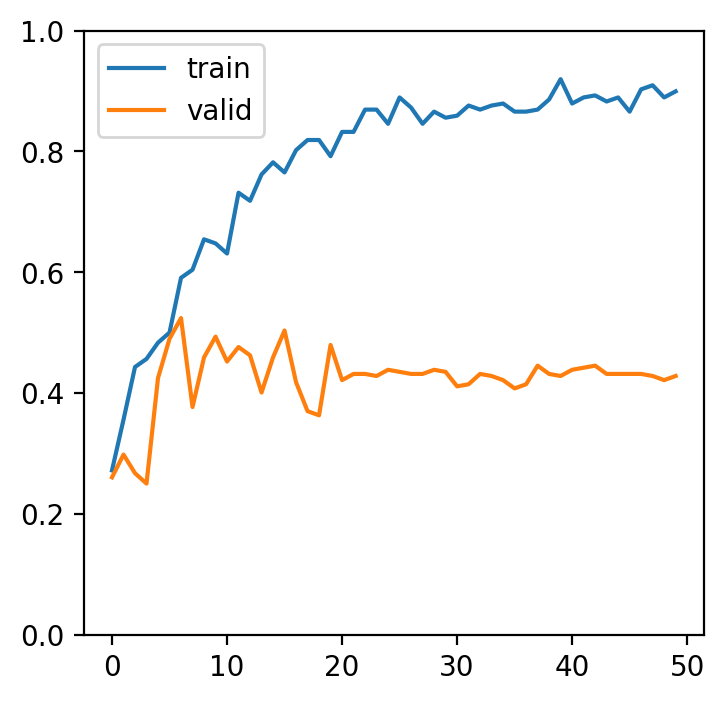
このグラフを見ると、data augmentation を行うと学習精度が 90% 前後に届いたものの、検証精度が 40% 前後であった。data augmentation を行なっていない例を見る(参考)では、学習精度と検証精度がともに 70% 以上である。これらの例から、やみくもに data augmentation を行なっても、精度の向上につながらないことがわかる。Data augmentation もしっかり考えて、画像の増幅を行うべきである。