このページでは畳み込みニューラルネットワークを利用して回帰問題を解く方法を示す。画像を使った回帰例として、顔写真から年齢を予測したり、ドローン画像から作物の収量を予測したりするなどが挙げられる。
このページでは MNIST のデータセットを使用する。MNIST データセットは手書きの 0, 1, 2, ..., 9 までの数値を認識するモデルを作成するために使用する画像データセットである。1 枚の画像に 1 つの数値が書かれている。画像のサイズは 26×26 ピクセルとなっている。画像が小さくかつ分類が簡単であることから、モデルを構築する際のサンプルデータとしてよく使われている。MNIST データセットは、本来は 1 枚の画像が与えられて、その画像が 0, 1, 2, ..., 9 のどれに分類されるのかという分類問題に使われる。このページでは、0 〜 9 までの正解ラベルを実数として捉えて、画像を入力しその値を直接予測するようなモデルを構築する例を示す。言い換えれば、顔写真を入力として、その年齢を予測するようなモデルを構築する方法を示す。
解析に必要なパッケージを読み込む。
import os
import numpy as np
import matplotlib.pyplot as plt
import PIL
import torch
import torchvisionデータの準備
分類問題では、画像を予めカテゴリごとにフォルダにまとめ、それらを ImageFolder 関数で読み込むと、学習や検証用に使えるようになる。回帰問題では、カテゴリが存在しないので、ImageFolder 関数が存在しない。そのため、ImageFolder のような関数を自ら定義する必要がある。
学習用の画像データが train フォルダにあり、検証用の画像データが valid フォルダにあるとする。train フォルダと valid フォルダの下にサブフォルダがなく、その下に画像がそのまま保存されている状態とする。そして、各画像のパスとその画像(顔写真)に対する値(年齢)の対応関係が train_labels.tsv および valid_labels.tsv の名前のテキストファイルに保存されているものとする。これらのファイルはタブ区切りで、2 列からなる。1 列目は画像へのパスで、2 列目がその画像に対する値(教師ラベル)を記録しているものとする。
これらの train_labels.tsv または valid_labels.tsv ファイルを読み込んで、画像データを準備する関数をここで定義する。つまり、ImageFolder のような関数をここで定義する。これらのファイルへのパスを、次の関数(クラス)の中では label_path という引数名にしてある。詳細な定義方法については、pytorch Dataloader を参照。
class MyDataset(torch.utils.data.Dataset):
def __init__(self, label_path, transform=None):
x = []
y = []
with open(label_path, 'r') as infh:
for line in infh:
d = line.replace('\n', '').split('\t')
x.append(os.path.join(os.path.dirname(label_path), d[0]))
y.append(float(d[1]))
self.x = x
self.y = torch.from_numpy(np.array(y)).float().view(-1, 1)
self.transform = transform
def __len__(self):
return len(self.x)
def __getitem__(self, i):
img = PIL.Image.open(self.x[i]).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img, self.y[i]上で定義した MyDataset クラスを使用して、画像データの読み込み準備を行う。
transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_data_dir = 'drive/My Drive/datasets/mnist/train_labels.tsv'
valid_data_dir = 'drive/My Drive/datasets/mnist/valid_labels.tsv'
trainset = MyDataset(train_data_dir, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
validset = MyDataset(valid_data_dir, transform=transform)
validloader = torch.utils.data.DataLoader(validset, batch_size=64, shuffle=False)モデルアーキテクチャの準備
簡単なアーキテクチャを用意する。以下に示したアーキテクチャのほか、VGG16 などの有名アーキテクチャを使用してもよい。この場合、VGG16 の出力層のユニット数を 1 に変更しておく必要がある。
class RegressionNet(torch.nn.Module):
def __init__(self):
super(RegressionNet, self).__init__()
self.conv1 = torch.nn.Conv2d(3, 16, 3)
self.pool1 = torch.nn.MaxPool2d(2, 2)
self.conv2 = torch.nn.Conv2d(16, 32, 3)
self.pool2 = torch.nn.MaxPool2d(2, 2)
self.fc1 = torch.nn.Linear(32 * 5 * 5, 1024)
self.fc2 = torch.nn.Linear(1024, 1024)
self.fc3 = torch.nn.Linear(1024, 1)
def forward(self, x):
x = torch.nn.functional.relu(self.conv1(x))
x = self.pool1(x)
x = torch.nn.functional.relu(self.conv2(x))
x = self.pool2(x)
x = x.view(-1, 32 * 5 * 5)
x = torch.nn.functional.relu(self.fc1(x))
x = self.fc2(x)
x = self.fc3(x)
return x
net = RegressionNet()
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
net = net.to(device)学習と検証
回帰問題の場合、損失関数として MSE を用いるのが一般的である。ここで、学習時のパラメーターなどを定義する。
optimizer = torch.optim.SGD(net.parameters(), lr=0.01)
criterion = torch.nn.MSELoss()学習と検証を 50 エポック行う。
train_loss = []
valid_loss = []
for epoch in range(50):
# 学習
net.train()
running_train_loss = 0.0
with torch.set_grad_enabled(True):
for data in trainloader:
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
running_train_loss += loss.item()
loss.backward()
optimizer.step()
train_loss.append(running_train_loss / len(trainset))
# 検証
net.eval()
running_valid_loss = 0.0
with torch.set_grad_enabled(False):
for data in validloader:
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
outputs = net(inputs)
running_valid_loss += loss.item()
valid_loss.append(running_valid_loss / len(validset))
print('#epoch:{}\ttrain loss: {}\tvalid loss: {}'.format(epoch,
running_train_loss / len(train_loss),
running_valid_loss / len(valid_loss)))50 エポックにおける学習損失と検証損失の変化をグラフで可視化する。
fig = plt.figure()
ax = fig.add_subplot()
ax.plot(train_loss, label='train')
ax.plot(valid_loss, label='valid')
fig.show()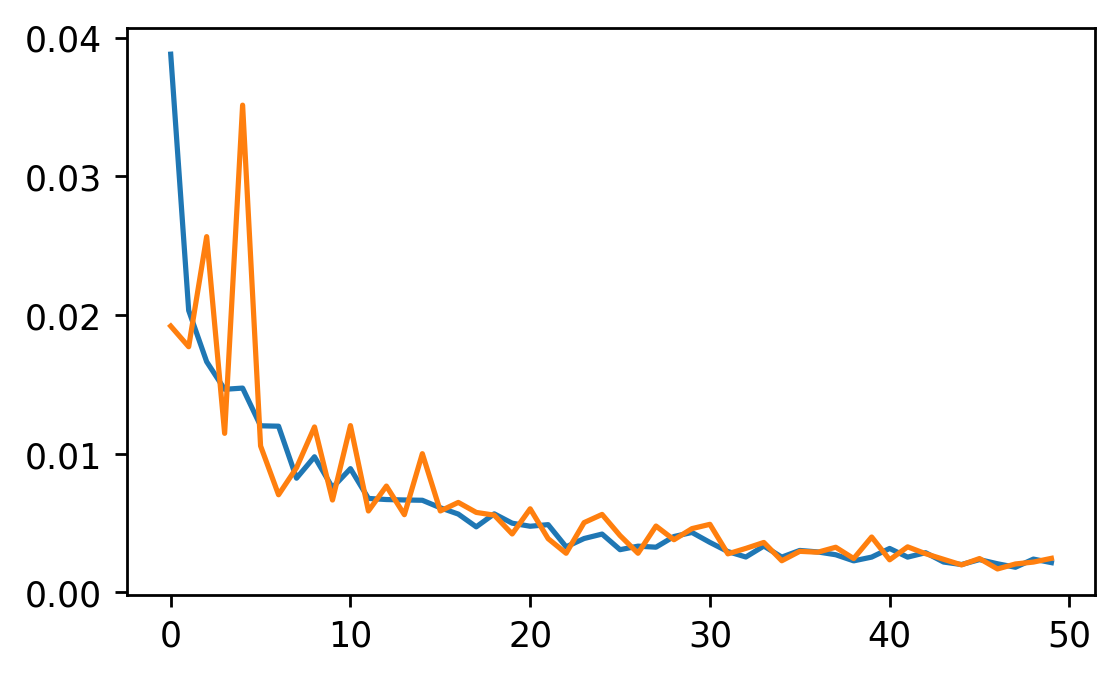
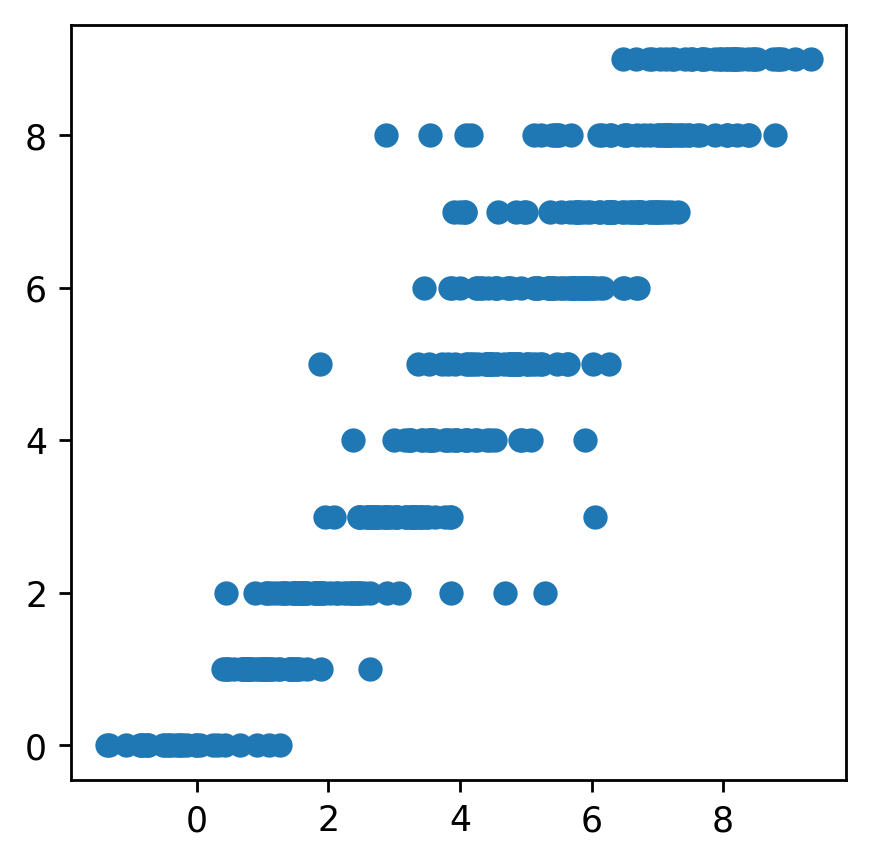
試しに、最後のエポックにおける最後のミニバッチの予測値と正解ラベルの関係をグラフで示す。なんかなく学習ができていることが確認できる。ただ、予測精度は、分類問題としてときの予測結果に比べたら、それほど高くはないように見える。
fig = plt.figure()
ax = fig.add_subplot()
ax.scatter(outputs.cpu().detach().numpy(), labels.cpu().detach().numpy())
fig.show()