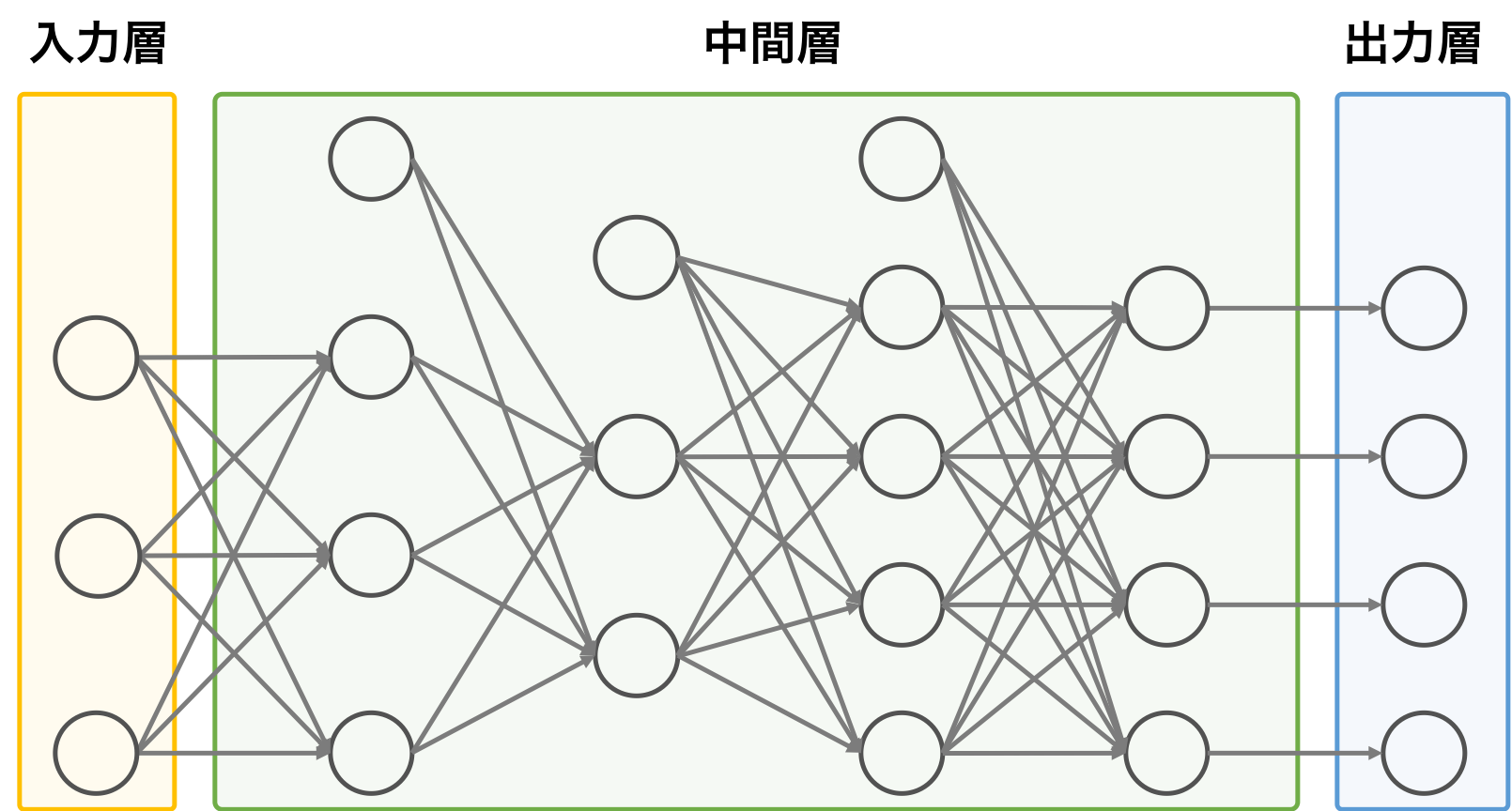
ニューラルネットワークの構成
ニューラルネットワークは、脳の神経細胞(ニューロン)とそのつながりを数理モデル化した概念である。ニューラルネットワークには、入力層、中間層(隠れ層)、出力層で構成されている。層と層の間は、ニューロンで繋がり、前の層の演算結果を次の層に渡す役割を果たす。パーセプトロンを複数の層を重ね合わせたようなものである。
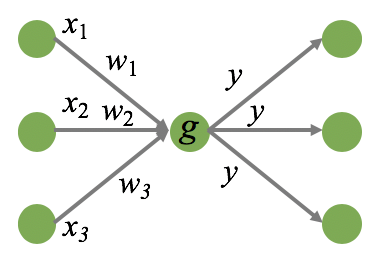
一つ一つのユニット(ニューロン)は直前の層から複数のシグナルを受け取り、それぞれにウェイトをかけてから、演算を行い、1 つの値を出力する。出力された値は、次の層にあるユニットの入力シグナルとなる。例えば、あるユニットの直前の層には 3 つのユニットがある場合、それぞれのユニットから出力される値(x1, x2, x3)を受け取って演算を行う。演算は、各入力値にウェイト(w1, w2, w3)をかけてから、総和を計算し、定数項 w0 を足す作業である。
\[ z = w_{0} + w_{1} x_{1} + w_{2} x_{2} + w_{3} x_{3}\]そして、その演算結果 z を活性化関数 g に代入し、y = g(z) の値を出力する。ここで出力された y は次の層のユニットの入力値となる。例えば、次の層のユニットが 3 つあれば、g(z) はその 3 つのユニットの入力値となる。
ニューラルネットワークモデルのハイパーパラメーター
ニューラルネットワークを利用して機械学習のモデルを作成するとき、ニューラルネットワークの構造・構成を決める必要がある。そのためには、モデルを作成するのに先立ち、下にリストアップしたような項目を決めておく必要がある。これらの項目に設定した値が、ニューラルネットワークの最終的な学習結果に及ぼすので、なんでもいいというわけにはいかない。実際には、解析対象となるデータのサンプル数やデータの特徴などに応じて、(あるいは過去の文献を探して、)いくつかの候補値を用意して、それらを総当たりで試して、もっともよい値を選ぶ、というのが行われている。
- ニューラルネットワークの構成
- 各層のユニット数
1 つの層に存在するユニット数を多くすることで、データに含まれている特徴を満遍なく取得できるようになる。入力データの特徴量の数よりも、ユニット数が著しく多いとき、過適合を起こしてしまう。逆に、入力データの特徴量の数よりも、ユニット数が少ないとき、入力データの特徴量が次元圧縮され、一部の情報が消えてしまうことがある。このようにユニットが多すぎても、少なすぎてもいけない。
最適なユニット数はデータの特徴などによって異なる。最適なユニット数を決めるには、そのデータを使用した過去文献を探して参考にするといい。また、ユニット数を 1 個から初めて、数個ずつ増やしながら、モデルの学習精度を評価していく。そして、モデルの学習精度が最大に達したときのユニット数を採用する。また、学習データを多く用意できるのであれば、ユニット数を多く設定しても、学習を通して、意味のないユニットにかかるウェイトがほぼゼロになるので、ユニット数を多めに設定しても構わない。 - 中間層の層数
最適な層数に関しても一定な規則はない。ただ、過去の文献を探してみると、入力層のユニット数と出力層のユニット数によって、中間層の層数を決めているというケースが見受けられる。
- 各層のユニット数
- ニューラルネットワークの学習
- 活性化関数
ステップ関数、シグモイド関数、ReLU 関数、ソフトマックス関数などの活性化関数を利用できる。中間層では ReLU 関数が要されている、出力層では一般的にソフトマックス関数などを用いる。 - 学習率
学習率は、モデルのパラメーターを更新するときに、現在の値からどのぐらいの幅で更新するのかを決める値である。学習率を小さくしすぎると、最適解に達するまでの時間(収束するまでの時間)が遅くなる。逆に、学習率を大きくしすぎると、最適解にたどり着けずに発散してしまう。ちょうど良い学習率を決めるには、いくつかの候補を決めて、学習率と最適解に到達するまでの関係を調べる必要がある。また、最適な学習率でなくても、予測が期待以上に精度高ければ、実用上それで十分だから、わざわざ最適な学習率を探す必要がないかもしれない。 - ミニバッチ
ミニバッチ学習を行うときにミニバッチのサイズを決める必要がある。全学習データが N 個で、ミニバッチサイズを n とすると、学習は N 個のデータの中からランダム n 個を取り出して行われる。ミニバッチのサイズを小さくすると、メモリの使用量が抑えられ、個々のデータの特徴が学習する際に反映されやすくなる。しかし、学習に要する時間が非常に長い。逆に、ミニバッチのサイズを大きくすると、学習は早く進むが、メモリ使用量なども増える。ミニバッチのサイズを大きくしすぎると、学習が収束しづらくなり、学習がかえって遅くなる。ミニバッチのサイズに関して、まず 32, 128 あたりから試して、最適な値に決めた方がいい。 - 学習アルゴリズム
確率的勾配降下法、Momentum 法、AdaGrad 法などのアルゴリズムが提唱されているが、過去文献を探して、よく使われているアルゴリズムを選択すればいい。あるいは、機械学習フレームワークに実装されているデフォルトのアルゴリズムを使っても良い。
- 活性化関数