R-CNN (Regions with CNN features) は、物体検出に用いられている深層学習アーキテクチャである。R-CNN では、入力画像からオブジェクトらしき領域を 2,000 領域を抽出し、それぞれの領域に対して、特徴を抽出し物体認識(画像分類)を行なっている(Girshick et al., 2014)。これにより、R-CNN は物体が存在している場所を検出し、その物体の種類を判別している。
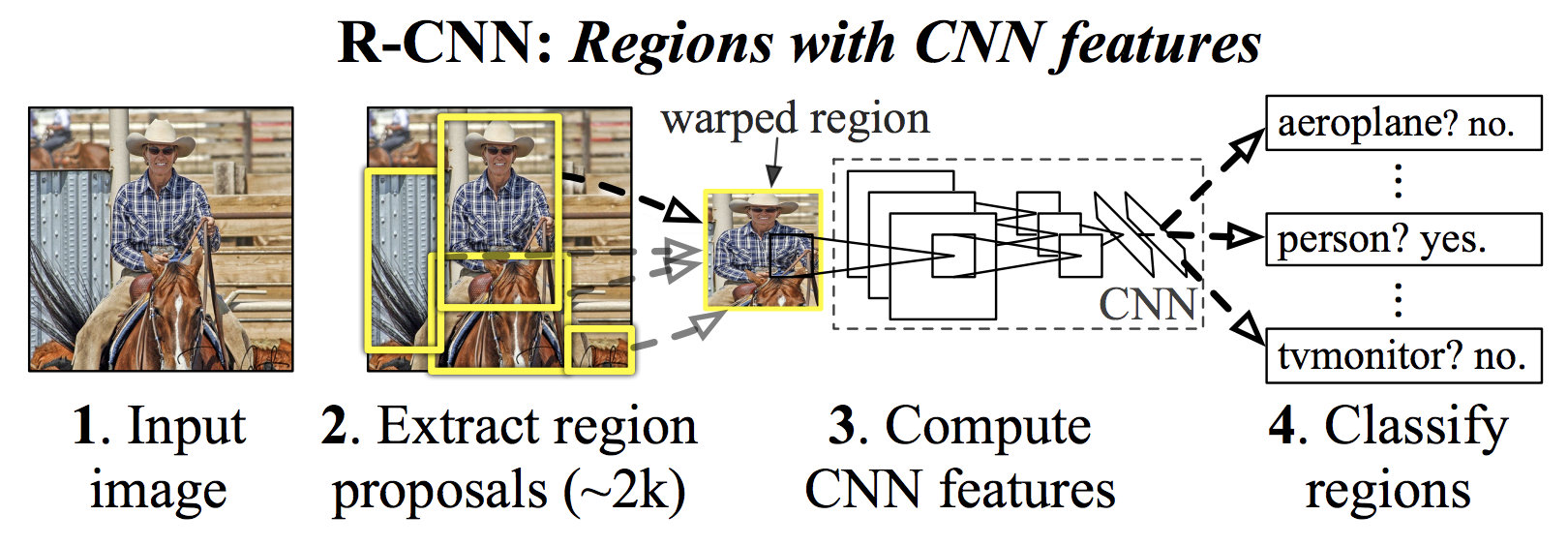
R-CNN では、入力された画像に対して、selective search (Uijlings et al., 2013) とよばれるアルゴリズムを使い、オブジェクトらしき領域を 2,000 候補を抽出している。続いて、検出された 2,000 箇所の候補それぞれに対して、特徴抽出の前処理として画像のサイズを調整する。特徴抽出は 227×227 の画像を入力とする必要があるので、各候補領域は wrap と呼ばれる処理によって、227×227 の正方形に変更される。続いて、この 227×227 の正方形からなる画像を畳み込みニューラルネットワーク(CNN)に入力し、出力として 4,096 次元の特徴ベクトルを得る。最後に、この4,096 次元の特徴ベクトルをサポートベクトルマシン(SVM)に入力され、画像分類が行われる。
R-CNN を使って高精度で物体検出が可能になった。しかし、R-CNN にいくつか改善すべき課題が残されていた。R-CNN の学習と予測は非常に時間がかかる処理であった。例えば、1 枚の画像から物体検出を行うには約 47 秒もの時間がかかり、動画解析への応用が難しかった。また、オブジェクト候補領域の検出に利用されている selective search アルゴリズムは、1 種の計算アルゴリズムであり、機械学習の予測アルゴリズムのように画像によって学習を進める必要がない。言い換えれば、画像の特徴が変わったとしても、selective search のアルゴリズムは変わることがなく、画像の特徴に応じて、最適な候補領域を検出できなかったりする。
References
- Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv. 2014. arXiv: 1311.2524
- Selective search for object recognition. IJCV. 2013.