Fast R-CNN は、物体検出に用いられている深層学習アーキテクチャである(Girshick et al., 2015)。Fast R-CNN は R-CNN と同様に、selective search (Uijlings et al., 2013) アルゴリズムを使用して、オブジェクトの候補領域を検出して、その候補領域に対して物体認識を行なっている。しかし、両者では、特徴量を抽出する際に利用している畳み込みニューラルネットワーク(CNN)が異なっており、また、特徴抽出と物体認識の順序が異なっている。
R-CNN は浅いニューラルネットワーク(AlexNet)を実装していたのに対して、Fast R-CNN はより深層なニューラルネットワーク(VGG16)を実装した。また、R-CNN ではオブジェクト候補領域を 2,000 箇所を検出して、それぞれの候補領域に対し、CNN で特徴量を抽出していた。これに対して、Fast R-CNN では、最初に一度だけ CNN を使って特徴量を抽出してから、候補領域に該当する部分のデータを切り出して使用している。CNN の実行回数が減ったことで、Fast R-CNN の処理時間は、R-CNN に比べて約 9 倍も速くなった。また、PASCAL VOC 2012 のデータセットを利用した性能評価において、R-CNN では 62% mAP(誤差)であったのに対して、Fast R-CNN は 66% であった。
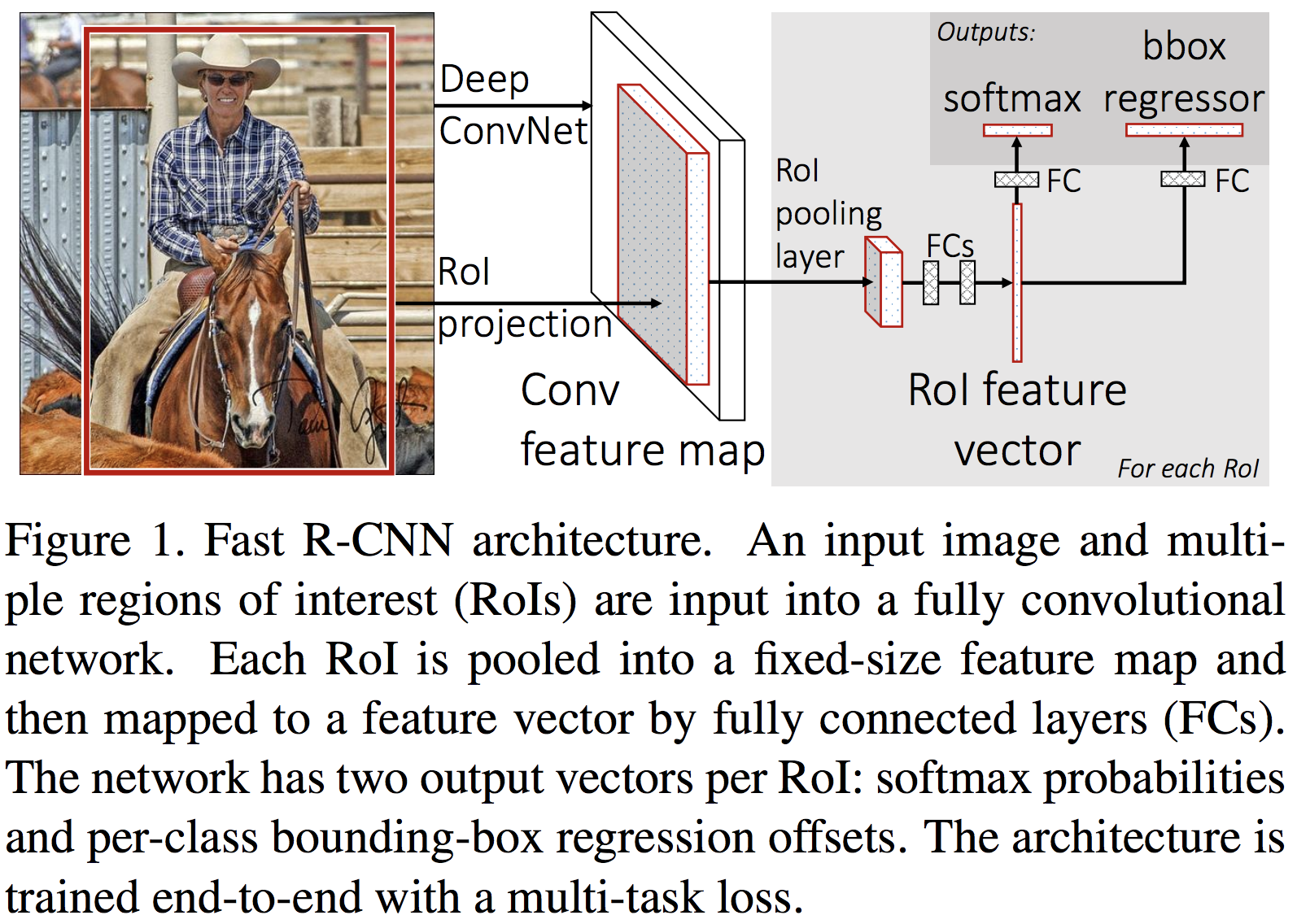
Fast R-CNN 論文の Figure 1 (Girshick et al., 2015)にあるように、Fast R-CNN では最初に 1 枚の入力画像全体に対して、畳み込み演算とプーリング演算を行なっている。その演算結果として convolution feature map が得られる。続いて、この convolution feature map の中で、オブジェクトの候補領域(RoI)に該当する領域を抽出して、それぞれの RoI に対して RoI pooling とよばれるプーリング演算を行う。この演算では、直前の畳み込み層から出力された画像に対して、例えば縦を 7 等分、横を 7 等分してからプーリング演算を行なっている。これにより、画像は、7×7 の画像に縮尺される。次に、この 7×7 の画像を全結合層に渡して、固定長の特徴ベクトルに変換する。続けて、この特徴ベクトルは、全結合層を介してソフトマックス関数が組み込まれた出力層に受け渡される。この層からは、RoI 中のオブジェクトはどのクラスに属しているのかを判定している。また、これとは独立に、特徴ベクトルは、全結合層を介して回帰関数が組み込まれた出力層に受け渡される。この層からは、オブジェクトを囲むバウンディングボックスの位置情報を示す実数値が出力される。
References
- Fast R-CNN. arXiv. 2015. arXiv: 1504.08083
- Selective search for object recognition. IJCV. 2013.