ResNet (residual networks) は、Microsoft の He らのチームによって開発されたアーキテクチャである(He et al., 2015)。この頃、ネットワークの層を深くすることで、画像判別の性能が上がることが一般的に知られるようになった。しかし、ネットワークの層をある程度深くすると、性能がかえって悪化することも明らかとなった。これに対処するために、He らは、residual learning とよばれる学習方法を導入し、この問題を解決させた。最終的に彼らは、層を 152 層まで深くすることができるようになった。2015 年に、画像分類チャレンジコンテスト ISLVRC-2015 で優勝した。
勾配消失問題
深い層を持つニューラルネットワークは、理論上、浅い層を持つニューラルネットワークに比べて高い性能を示すか、あるいは同等な性能を示す。例えば、20 層のニューラルネットワークで十分に学習できデータを、56 層からなるニューラルネットワークに学習させたとき、パラメータが多い分だけより多くのことを学習できるはずである。あるいは、21〜56 層目を恒等関数とすることで、56 層のニューラルネットワークは、見かけ上 10 層のニューラルネットワークと同等な性能を示すはずである。
VGGNet の論文で調べられたように、層を深くすることで確かに性能が良くなった。しかし、層をさらに深くしていったとき、例えば 20 層と 56 層からなるニューラルネットワークの性能を比較したときに、56 層のニューラルネットワークの性能は、20 層のニューラルネットワークに比べて、明らかに劣っていたことがわかった(He et al., 2015)。これは、層が深くなっていったとき、ニューラルネットワークの前方にある層(入力層に近い層)の学習が非常に遅くなっているからである。訓練データで学習するときに生じた損失は、ニューラルネットワークの後方(出力層)から前方(入力層)に向けて伝播される。この損失は、層を遡っていくほど、小さくなっていく。そのため、ニューラルネットワークの層が深くなると、損失が前方の層に到達したときにはほどんどなくなっている。ニューラルネットワークの学習では、損失を小さくするように学習を進めている。そのため、損失が大きいと学習は早く進むが、損失がほとんどない状況では学習がほとんど行われなくなる。これが、勾配消失問題といわれている。
ResNet は residue learning とよばれるアーキテクチャを取り入れて、勾配消失問題を解決した。これを受け、ResNet は、152 層をも持つ深層なニューラルネットワークであるにもかかわらず、高性能を示している。
residue learning
ニューラルネットワークのある層において、入力 x を受け取り、それに対して何らかの演算を行い、その演算結果 y を出力している。ニューラルネットワークで行われる演算処理に使われるパラメータは、学習によって決定される。演算処理を行う関数(写像)を H とすると、一般的なニューラルネットワークでは、入力 x を受けとると、y = H(x) として y を出力している。
ResNet に用いられている residue learning でも、一般的なニューラルネットワークと同様に、入力 x を受け取り、関数 H で処理した結果である H(x) を y として出力している。ただし、一般的なニューラルネットワークでは、学習を通じて関数 H を求め(推定して)、出力 y = H(x) を直接に計算している(下図左)。これに対して、residue learning では、関数 H を求める代わりに、入力 x と出力 y の差に着目して、間接的に y = H(x) を求めている。入力 x と出力 y = H(x) の差を F(x) と定義すると、F(x) = H(x) - x とかける。このとき、式変換により、出力 y は、y = H(x) = F(x) + x が得られる。よって、出力 y を計算するためには、残差である F が求まれば十分である。このように、residue learning では、学習を通じて残差 F を決定し、間接的に出力 y = H(x) を求めている。

まとめると、一般的なニューラルネットワークと ResNet は、どちらも入力データ x を受け取り、写像後のデータ y = H(x) を出力している。しかし、ニューラルネットワークの学習時において、一般的なニューラルネットワークは写像 H (のパラメーター)を学習しているのに対して、ResNet は残差 F を学習している。
residue block
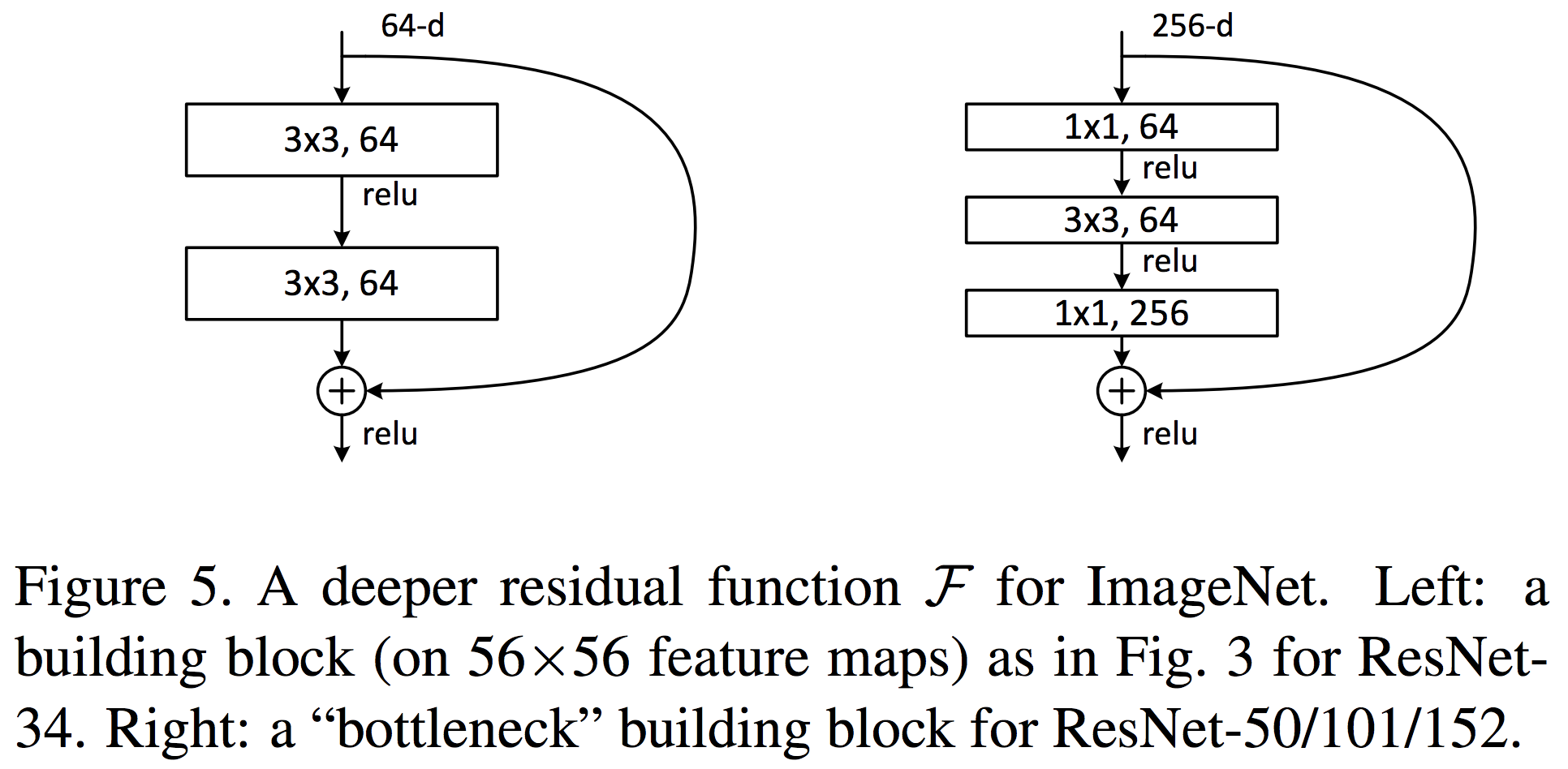
ResNet では、residue learning を 1 つのブロックにまとめて、下図のように実装している(Figure 5, He et al., 2015)。ResNet-34 には、上で定義した residue block をそのまま使っている。この residue block では 64 チャンネルからなる画像を入力とし、2 回の畳み込み演算を行なって 64 チャンネルの画像を出力している。これに対して、層の深い ResNet-50/101/152 では、256 チャンネルの画像を 1×1 Convolution (Lin et al., 2014)で 64 チャンネルに変換してから、1 回の畳み込み演算を行い、その後、再び 1×1 Convolution を使って画像のチャンネル数を 256 に変換して出力している。
References
- Network In Network. arXiv. 2014. arXiv: 1312.4400
- Deep Residual Learning for Image Recognition. arXiv. 2015. arXiv: 1512.03385