GoogLeNet (Szegedy et al., 2014) は、VGGNet とは独立に開発されたアーキテクチャであり、2014 年の画像分類チャレンジコンテスト ISLVRC-2014 で 1 位を獲得した。GoogLeNet のアーキテクチャは、AlexNet、ZFnet などの既存のアーキテクチャとは大きく異なり、1×1 Convolution、global average pooling (Lin et al., 2014)、および Inception モジュールなどの技術が新たに導入された。GoogLeNet は、この Inception モジュールを取り入れたことで、層を深くすることができるようになり、全体で 22 層で構成されている。
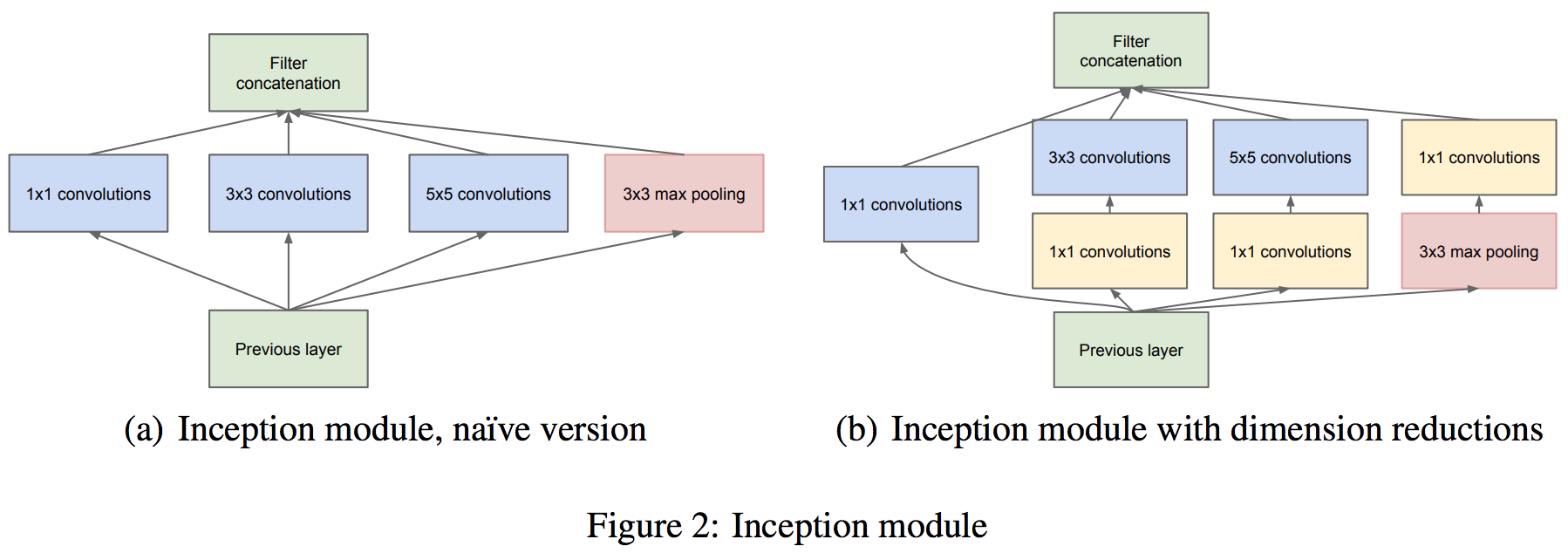
Inception モジュール
Inception モジュールの導入は、アーキテクチャの層を深くすることを可能にした。2013-2014 年当時、層を深くしたり、各層に存在しているユニットの数を増やしたりすることで、分類の性能が上がることが知られ始めた。しかし、少ないデータの中で、層数やユニット数を増やすことで、過学習を起こしてしまう。そこで、開発者らは Inception と呼ばれるモジュールを作り、その Inception モジュールを重ねていくことで、層を深くすることができた。
これまでのアーキテクチャは、畳み込み層を順列に繋げていた。このため、畳み込み層が深くなるにつれ、画像サイズが小さくなっていき、層を深くすることができなかった。これに対して、GoogLeNet では、1 つの入力画像に対して、複数の畳み込み層(1×1, 3×3, 5×5)を並列に適用し、それぞれの畳み込み計算の結果を最後に連結している。この一連の作業をモジュールとしてまとめられ、Inception モジュールと呼ばれている。Inception モジュールを多数使うことで、パラメーターが膨大な数になる。そこで、GoogLeNet では、各畳み込み計算を行う前に 1×1 Convolution を行い、パラメーター数を削減している。
Inception モジュールの構造は GoogLeNet 論文の Figure 2 で確認できる(Szegedy et al., 2014)。Figure 2a は Inception モジュールの基本構造を示している。Figure 2b は 1×1 Convolution を組み込んだ Inception モジュールの構造を示している。
global average pooling
従来の画像分類アーキテクチャでは、最後の層に全結合層が用いられている。全結合層では、層間のパーセプトロンが互いにすべて結合している。そのため、パラメーター数が多く、過学習を起こしやすいことが知られていた。そこで、GoogLeNet では、最後の層で全結合層の代わりに、global average pooling とよばれる技術を取り入れている。
GoogLeNet では、最後の畳み込み層において、チャンネル数をクラス数と同じになるように畳み込み計算を行っている。例えば、100 クラスの分類問題では、最後の畳み込み層で、100 チャンネルのとなるようにする。続いて、各チャンネルに対して、画素平均を計算し、最終的にはチャンネル数分の要素を持ったベクトルが得られる。このベクトルに対してソフトマックス関数を適用することで、クラスの分類結果が得られるようになる。
Inception v1/v2/v3/v4
GoogLeNet にはいくつかのバリエーションが存在する。ISLVRC-2014 で優勝した最初に発表されたバリエーションは Inception v1 と呼ばれている。その後、Inception モジュールに含まれている畳み込みフィルターのサイズを変更した Inception v2、そして Inception v2 に対してさらに改良を加えた Inception v3 が開発された(Szegedy et al., 2015)。さらに、その後も改良が行われ、Inception v4 や ResNet を取り込んだ Inception-ResNet が開発された(Szegedy et al., 2016)。
References
- Network In Network. arXiv. 2014. arXiv: 1312.4400
- Going Deeper with Convolutions. arXiv. 2014. arXiv: 1409.4842
- Rethinking the Inception Architecture for Computer Vision. arXiv. 2015. arXiv: 1512.00567
- Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv. 2016. arXiv: 1602.07261